研究生课程:现代信息检索-第1讲 布尔检索
《现代信息检索》课程笔记:第1讲 布尔检索
第1讲 布尔检索
信息检索概述
现在提到信息检索,通常会首先想到Web搜索,但是除此之外还有很多其它的搜索应用,如电子邮件搜索、笔记本电脑(桌面)搜索、知识库搜索、法律文献搜索等。
本课程主要关注文本检索,因为文本检索是最早的检索应用,也仍然是目前最主要的应用,且文本检索理论可以用于其他领域。
信息检索与数据库的区别主要在于数据的区别,信息检索关注的是非结构化的数据,而数据库关注的是结构化的数据。
数据库常常支持范围或者精确匹配查询。
非结构化数据通常指自由文本,允许关键词加上操作符号的查询和更复杂的概念性查询,经典的检索模型一般都针对自由文本进行处理。
信息检索的一些基本概念
文档集(Collection): 由固定数目的文档组成
目标:返回与用户需求相关的文档并辅助用户来完成某项任务
相关性(Relevance):主观的概念,反映对象的匹配程度不同,应用相关性不同。
检索效果的评价:准确率和召回率(准确率是自己的,召回率才是真正的)
布尔检索:针对布尔查询的检索,布尔查询是指利用 AND,OR或者 NOT操作符将词项连接起来的查询。
索引方法
需求:莎士比亚的哪部剧本包含Brutus及Caesar但是不包含Calpurnia
将需求表示为布尔表达式: Brutus AND Caesar AND NOT Calpurnia
暴力索引方法
从头到尾扫描所有剧本,对每部剧本判断它是否包含Brutus AND Caesar ,同时又不包含Calpurnia
暴力方法的优点:①实现简单②很容易支持文档动态变化
暴力方法的不足:
- 速度超慢 (特别是大型文档集)
- 处理NOT Calpurnia 并不容易(不到末尾不能停止判断)
- 不太容易支持其他操作 (e.g., 寻找靠近countrymen的单词Romans)
- 不支持检索结果的灵活排序 (排序时只返回较好的结果)
倒排索引
关联矩阵:
| Antony and Cleopatra | Julius Caesar | The Tempest | Hamlet | Othello | Macbeth | |
|---|---|---|---|---|---|---|
| Antony | 1 | 1 | 0 | 0 | 0 | 1 |
| Brutus | 1 | 1 | 0 | 1 | 0 | 0 |
| Caesar | 1 | 1 | 0 | 1 | 1 | 1 |
| Calpurnia | 0 | 1 | 0 | 0 | 0 | 0 |
| Cleopatra | 1 | 0 | 0 | 0 | 0 | 0 |
| mercy | 1 | 0 | 1 | 1 | 1 | 1 |
| worser | 1 | 0 | 1 | 1 | 1 | 0 |
行表示单词,列表示文本,若文本中包含这个单词,则记录为1,反之记录为0
使用关联矩阵进行查询的时候,即将关联矩阵有关单词的行向量取出来后进行按位与或非操作即可。
但是这种词项-文档的关联矩阵将非常大,由于是 one-hot存储,矩阵高度稀疏,需要更好的表示方式,因此有了倒排索引。
对每个词项 t,记录所有包含 t的文档列表,每篇文档用一个唯一的 docID来表示,通常是正整数。
词典 ➡ 倒排记录(Posting)
Brutus ➡ 1 2 4 11 31 45 173
Calpurnia ➡ 1 2 4 5 6 16 57 132
Caesar ➡2 31 54 101
倒排索引的存储通常采用变长表方式
- 磁盘上,顺序存储方式比较好,便于快速读取
- 内存中,采用链表或者可变长数组方式,便于节省空间
构建倒排索引的流程
文本预处理:
- 词条化(Tokenization):将字符序列切分为词条
- 规范化(Normalization):将文档和查询中的词项映射到相同的形式
- 词干还原(Stemming):将同一词汇的不同形式还原到词根
- 停用词去除(Stopwords removal):去除高频词项
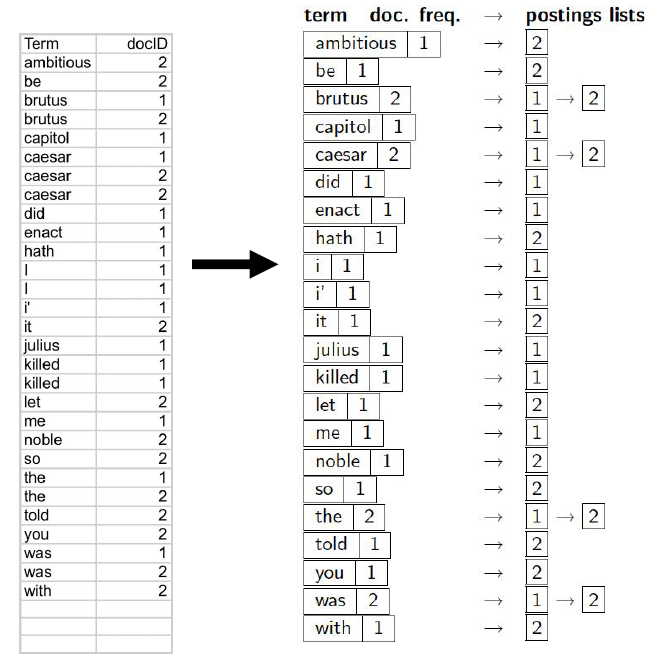
构建词条序列:<词条,docID> 类型的二元组
按词项排序:每个词项按 docID排序
某个词项在单篇文档中的多次出现会被合并
拆分成词典和倒排记录表两部分
每个词项出现的文档数目(doc.frequency, DF)会被加入
最终构成倒排索引:
布尔查询的处理
对于布尔查询来说,对倒排记录表进行操作即可。
每个倒排记录表都有一个定位指针,两个指针同时从前往后扫描, 每次比较当前指针对应倒排记录,然后移动某个或两个指针。合并时间为两个表长之和的线性时间。时间复杂度为 O(m+n)
这也是倒排记录表按照 docID排序的关键原因!
查询处理中存在处理的顺序问题:n个词项的 AND我们希望查询的次数越少越好,因此要按照表从小到大(即 df从小到大)的顺序进行处理,每次从最小的开始合并(这样可以尽量提前结束合并)
按照直接加和的方式对 Or的 df进行估计。
合并策略
每个布尔表达式都能转换成(合取范式)
获得每个词项的 df
通过将词项的 df相加,估计每个 OR表达式对应的倒排记录表的大小
按照上述估计从小到大依次处理每个 OR表达式
布尔检索的优点
构建简单,是构建信息检索系统的一种最简单方式
- 在30多年中是最主要的检索工具
- 当前许多搜索系统仍然使用布尔检索模型
- 有一些扩展的布尔操作符
- 如果非常清楚想要查什么、能得到什么,很多专业人士喜欢使用布尔搜索
布尔检索的缺点
- 布尔查询构建复杂,不适合普通用户。构建不当,检索结果过多或者过少
- 没有充分利用词项的频率信息。因为词通常出现的越多越好,需要利用词项在文档中的词项频率(term frequency, tf)信息
- 不能对检索结果进行排序