研究生课程:现代信息检索-第2讲 索引构建
《现代信息检索》课程笔记:第2讲 索引构建
语料通常很大,而服务器内存通常相对较小,因此需要在内存有限的情况下的索引构建策略。
第2讲 索引构建
词项:一个语料中不同的词的数量
词条:一个语料中所有词的数量(包括重复的)
基于排序的索引构建方法存在的问题
在构建索引时,每次解析一篇文档,因此对于每个词项而言,其倒排记录表不到最后一篇文档都是不完整的。
如果每个 (termID, docID)对占用 8个字节, 那么处理大规模语料需要大量的空间。
一般内存的容量比较小,没有办法将前面产生的倒排记录表全部放在内存中,需要在磁盘上存储中间结果。
内存和硬盘
内存的典型配置是几G ~ 几十G的内存或上百G或1-2T
磁盘空间通常有几T(小型服务器)或10T以上(磁盘阵列)
硬盘空间更大,但是在内存中访问数据会比从硬盘访问数据快很多(大概10倍以上的差距)
硬盘寻道时间是闲置时间:磁头在定位时不发生数据传输(假设使用的是机械硬盘)
因此一个大(连续)块的传输会比多个小块(非连续)的传输速度快
硬盘 I/O是基于块的:读写时是整块进行的。块大小:8KB到256KB不等
不能在硬盘上对倒排索引表进行排序,因为寻道的时间很慢,导致排序的时间也很慢。
BSBI算法
一种减少寻道操作的排序:Blocked sort-based Indexing
将所有记录划分为每个大小约为10M的块,收集每一块的倒排记录,排序,将倒排索引写入硬盘,最后将不同的分块合并为一个大的倒排索引。
关键决策:块的大小-块越大,最后的合并操作就越少
合并的过程中需要在磁盘中同时保存数据的两份拷贝(合并前与正在合并),因此磁盘空间要足够大。
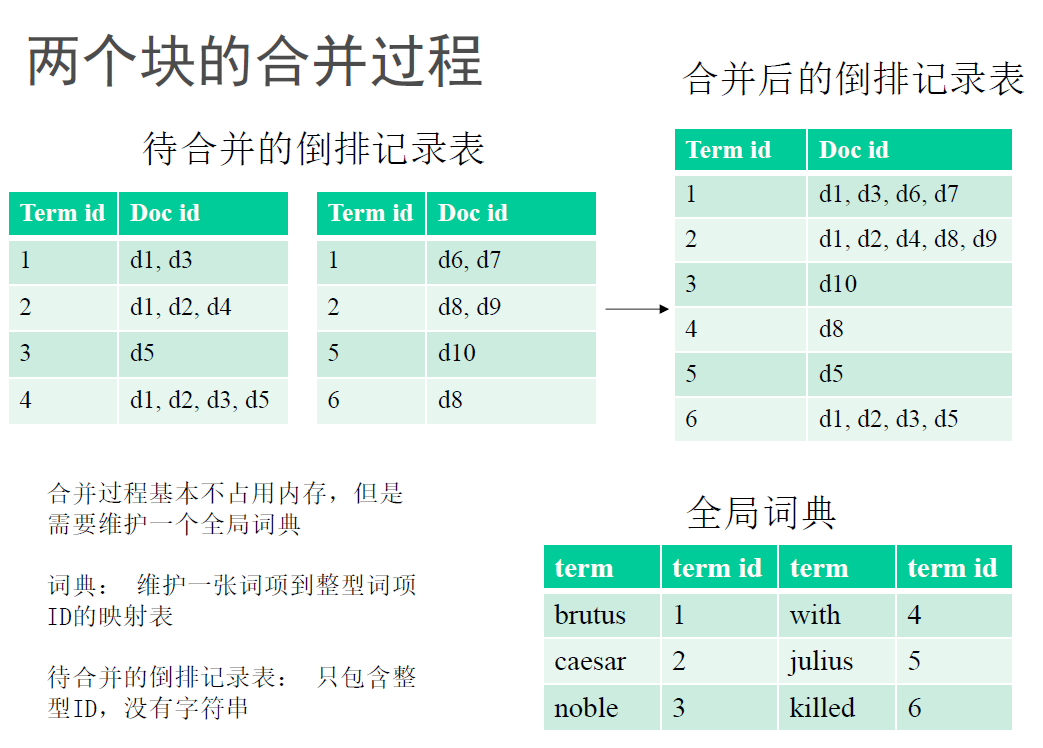
词项字符串的占用空间比较大,因此维护一个全局词典来将字符串映射到唯一的全局ID
合并的过程中,将每一个小块的一点点数据放入内存中进行排序,排序好了就放在写缓冲区中,写缓冲区满了就写回硬盘,直到排序完成。
可以将两两合并的方式优化为多项合并(multi-way merge):
- 从所有块同时读取,并且为每块保持一个读缓冲区(read buffer)
- 为输出文件(即合并后的索引)保持一个写缓冲区(write buffer)
- 维护一个待处理
termid的优先级队列(priority queue),每次迭代从队列中选取一个最小的未处理termid - 合并不同块中所有的该
termid的倒排记录,并写入磁盘。 - 因此每次迭代均处理较小规模的数据(一个词项的倒排记录)。
BSBI算法的问题:
- 假定词典可以在内存中放下
- 通常需要一部词典(动态增长)来将
term映射成termID。实际上倒排记录表可以直接采用(term,docID)方式而不是
(termID,docID)方式,但是此时中间文件(即待合并的倒排记录表)将会变得很大(字符串比整型数空间消耗更大)
SPIMI算法
内存式单遍扫描索引构建算法:Single-pass in-memory indexing
关键思想:
- 对每个块都产生一个独立的词典(不需要在块之间进行
term-termID的映射) - 对倒排记录表不排序,按照它们出现的先后顺序排列,只对词典排序(实际上由于指针的存在,倒排记录表没有排序的必要)。
在扫描文档的同时,直接在内存中维护一个不断更新的倒排索引
因此对每个块生成一个完整的倒排索引,这些独立的索引最后合并成一个大索引
最终合并词典的过程中,需要进行词项字符串的比较,因为此时没有全局词典提供词项-整数ID的映射。
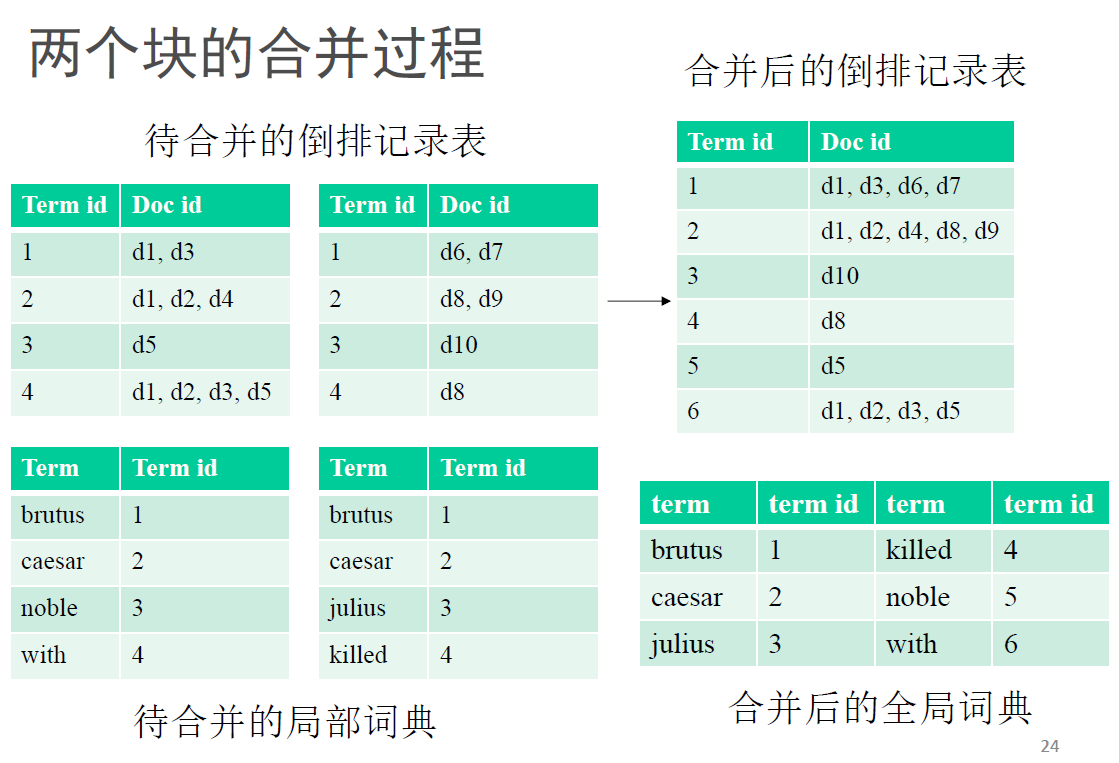
BSBI算法和SPIMI算法的主要区别
BSBI算法:在分块索引阶段,BSBI算法维护一个全局Term (String) – Termid (int) 的映射表,局部索引为Termid及其倒排记录表,仍然按词典顺序排序。
SPIMI算法:分块索引阶段与BSBI算法不同在于建立局部词典和索引,无需全局词典。在合并阶段,将局部索引两两合并,最后产生全局词典建立Term – Termid的映射。
动态索引构建
实际中文档会增加、删除和修改,因此词典和倒排记录表必须要动态更新。
最简单的方法:主索引(Main index)+辅助索引(Auxiliary index)
- 在磁盘上维护一个大的主索引(Main index)
- 新文档放入内存中较小的辅助索引中
- 同时搜索两个索引,然后合并结果
- 定期将辅助索引合并到主索引中
删除的处理:
- 采用无效位向量(Invalidation bit-vector)来表示删除的文档
- 利用该维向量过滤返回的结果,以去掉已删除文档
问题:
- 合并过于频繁
- 合并时如果正好在搜索,那么搜索的性能将很低
辅助索引方式: 每次合并都需要处理每个倒排记录,索引构建时间为
对数合并(Logarithmic merge):
对数合并算法能够缓解(随时间增长)索引合并的开销 → 用户并不感觉到响应时间上有明显延迟。
- 维护一系列索引,其中每个索引是前一个索引的两倍大小
- 将最小的索引
置于内存
- 将其他更大的索引
置于磁盘
- 如果
,则将它作为 $I_0 $写到磁盘中(如果 $I_0 $不存在)
- 或者和
合并(如果
写到磁盘中(如果
因此每次两两合并中两个索引的大小相同
索引数目的上界为