机器学习算法竞赛实战-用户画像
机器学习算法竞赛实战-用户画像
第7章 用户画像
用户:产品的使用者
数据收集方为了推广产品同时持续维护和改善用户体验需要对由用户操作而产生的数据进行挖掘,以期从中发现群体乃至个体的行为偏好,形成数据层面上的所谓画像。
用户画像
用于商业分析和数据挖掘的用户画像。基于给定的数据对用户属性及行为进行描述,然后提取用户的个性化指标,再以此分析可能存在的群体共性,并落地应用到各种业务场景中。
标签系统
核心就是给用户打标签,用来分析社会属性、社会习惯、生活习惯、消费行为。
标签分类方式
通过分析一个用户的特征来展示标签分类方式:
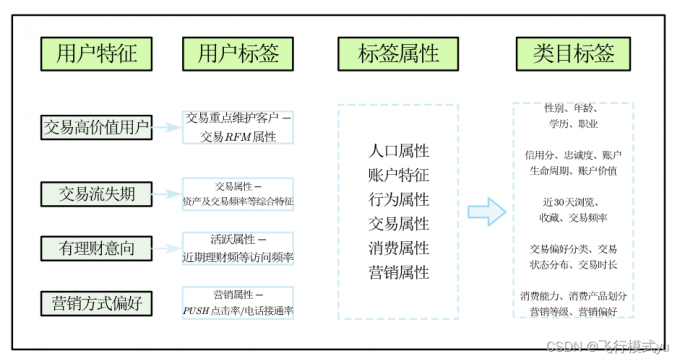
多渠道获取标签
标签获取方式也可以看作特征获取方式
事实类:直接来自原始数据,比如性别、年龄、会员等级。也可以进行简单统计,比如用户行为次数、消费总额。
规则类:由运营人员和数据人员经过共同协商设定。例如,地域属性、家庭类型、年龄层等。所用技术知识:数理统计类,如基础统计、数值分层、概率分布、均值分析、方差分析等。
模型类:经过机器学习和深度学习等模型处理后,二次加工生成的洞察性标签。比如预测用户状态、预测用户信用分、划分兴趣人群和对评论文本进行分类。特点:综合程度高、复杂,依托数学建模,多种算法组合。
标签体系框架
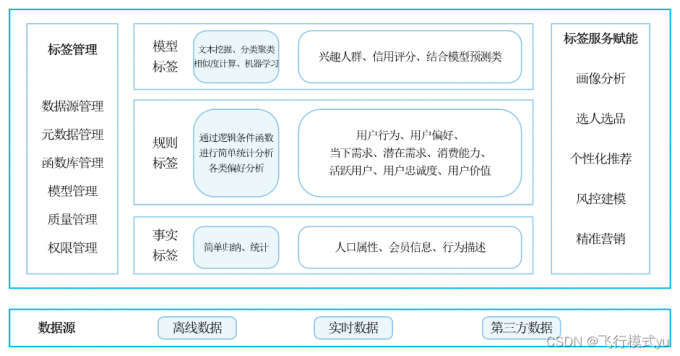
用户画像数据特征
常见的数据形式
- 数值型变量
- 类别型变量
- 多值型变量:用户在某个维度具有多个取值的变量
- 文本型变量:利用文本记录的变量。需要NLP知识,例如jieba中文分词工具
文本挖掘算法
LSA:非概率主题模型,与词向量有关,主要用于文档的话题分析。其核心思想是通过矩阵分解的方式发现文档和词之间基于话题的语义关系。
具体:将文档集表示为词-文档矩阵,对矩阵进行SVD(奇异值分解),从而得到话题向量以及文档在话题向量的表示。
举例:2020腾讯广告大赛,首先构造用户点击的广告素材id序列(creative_id),然后进行TF-IDF计算,最后经过SVD得到结果。
(代码与书中不同,未验证)
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# 稀疏特征降维 TruncatedSVD
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline
# 提取用户点击序列
docs = data_df.groupby(['user_id'])['creative_id'].agg(lambda x:"".join(x)).reset_index()['creative_id']
# tf-idf
tfd = TfidfVectorizer()
svd = TruncatedSVD(n_components=100, n_iter=50, random_state=2020)PLSA:PLSA(概率潜在语义分析)模型是为了克服LSA模型潜在存在的一些缺点而提出的。通过一个生成模型来为LSA赋予概率意义上的解释。该模型假设每一篇文档都包含一系列可能的潜在话题,文档中的每一个词都不是凭空产生的,而是在潜在话题的指引下通过一定的概率生成的。
LDA:LDA(潜在狄利克雷分布)是一种概率主题模型,与词向量无关,可以将文档集中的每篇文档的主题以概率分布的形式给出。通过分析一批文档集,抽取出他们的主题分布,就可以根据主题进行聚类或分类。同时,它是一种典型的词袋模型,即一篇文档由一组相互独立的词构成,词和词之间没有先后顺序。
神奇的嵌入表示
word2Vec:可调用gensim包,参数:窗口大小、模型类型选择、生成词向量长度
对于Skip-Gram和CBOW:
- CBOW在训练时比Skip-Gram快
- CBOW可以更好地表示常见单词
- Skip-Gram在少量的训练集中可以表示稀有单词或短语
DeepWalk
对于Word2Vec的衍生Item2Vec以及更多图嵌入方法,比如LINE、Node2Vec和SDNE
相似度计算方法
- 欧式距离
- 余弦相似度
- Jaccard相似度
用户画像的应用
用户分析
- 京东JDATA平台2019年的“用户对品类下店铺的购买预测”
- 腾讯广告“2020腾讯广告大赛”
精准营销
- 2018科大讯飞AI营销算法大赛
- 2018腾讯广告算法大赛
风控领域
- DF竞赛平台的“消费者人群画像-信用智能评分”
- 拍拍贷“第四届魔镜杯大赛”
特点:
- 业务对模型解释性比较高,对时效性有一定要求,需要权衡模型复杂度和精度,并且适当优化算法内核
- 业务模型多样,需要紧密结合业务
- 负样本极少,均衡学习算法
第8章 实战案例
参考资料:《机器学习算法竞赛实战》整理 | 八、实战案例:Elo Merchant Category Recommendation
赛题理解
Imagine being hungry in an unfamiliar part of town and getting restaurant recommendations served up, based on your personal preferences, at just the right moment. The recommendation comes with an attached discount from your credit card provider for a local place around the corner!
Right now, Elo, one of the largest payment brands in Brazil, has built partnerships with merchants in order to offer promotions or discounts to cardholders. But do these promotions work for either the consumer or the merchant? Do customers enjoy their experience? Do merchants see repeat business? Personalization is key.
Elo has built machine learning models to understand the most important aspects and preferences in their customers’ lifecycle, from food to shopping. But so far none of them is specifically tailored for an individual or profile. This is where you come in.
In this competition, Kagglers will develop algorithms to identify and serve the most relevant opportunities to individuals, by uncovering signal in customer loyalty. Your input will improve customers’ lives and help Elo reduce unwanted campaigns, to create the right experience for customers.
赛题数据
train.csv训练数据集,包括first_active_month,card_id,feature_1,feature_2,feature_3,target字段test.csv测试数据集,包括first_active_month,card_id,feature_1,feature_2,feature_3字段
first_active_month表示的是信用卡产生第一笔交易的时间,feature是信用卡类型的脱敏特征。最后一列 target是要预测的数值
historical_transactions.csv 信用卡在给定商家的历史交易记录,文件比较大,基本都是一些脱敏的特征
merchants.csv所有商家的附加信息
new_merchant_transactions.csv two months’ worth of data for each card_id containing ALL purchases that card_id made at merchant_ids that were not visited in the historical data .(每张信用卡在新商家的购物数据)
评价指标使用RMSE
