研究生课程:机器学习-第10章 神经网络与深度学习
《机器学习》课程笔记:第10章 神经网络与深度学习
第10章 神经网络与深度学习
概述
背景与现状
ANN到DL的技术发展
- ANN始于1890年:开始于美国心理学家W.James对于人脑结构与功能的研究。
- M-P模型 (1943 年):神经科学家麦卡洛克和数学家皮兹建立了神经网络和数学模型(MP模型),人工神经网络的大门由此开启。
- Hebb学习规则(1949年):加拿大著名心理学家唐纳德·赫布提出了Hebb学习规则,这是一种无监督的学习规则。 Hebb学习规则表明了网络是可以学习的,这启发了后面一系列关于神经网络的研究工作。
- 感知机(1958 年):心理学家Frank Rosenblatt受到Hebb思想的启发提出了感知机。感知机是最早的人工神经网络,也是具有学习功能M-P模型。整个1958 年-1969年期间,有许多科学家和学者都投入到了感知机研究。但是由于当时的计算水平相对落后,计算也显得很吃力。
- 1969年进入冰河期:马文明斯基在发表《 Perceptrons 》时,证明了感知器的致命弱点:不能够解决异或问题。
- 神经网络(1986 年)BP 算法:Rumelhar和Hinton提出了反向传播算法(BP 算法),是一种监督学习算法,解决了两层神经网络计算的复杂性。
- 卷积神经网络(1989年):1989年, LeCun发明了卷积神经网络LeNet,并将其用于数字识别,且取得了较好的成绩,不过当时并没有引起足够的注意。
- RNN模型:递归(recurrent)的现代定义由Jordan(1986 年),随后Elman(1990 年)的RNN网络。
- LSTM模型(1997年):LSTM的提出,尽管该模型在序列建模上的特性非常突出,但由于正处于ANN 的下坡期,也没有引起足够的重视。
- 深层信度网络(2006 年):2006DL元年,Hinton提出了深层网络训练中梯度消失问题的解决方案: 无监督预训练对权值进行初始化,并
进行有监督训练微调 。但是由于没有特别有效的实验验证,该论文并没有引起重视。 - ReLU激活函数(2011 年):该激活函数能够有效的抑制梯度消失问题。
- 语音识别突破(2011 年):微软首次将DL 应用在语音识别上,取得了重大突破。
- ImageNet竞赛夺冠(2012 年):Hinton团队首次参加ImageNet图像识别比赛,其通过构建的AlexNet网络一举夺得冠军。
- AlphaGo (强化学习):2016年 3 月人工智能围棋比赛,谷歌( Google )旗下 DeepMind 公司的戴维 · 西尔弗、艾佳 · 黄和戴密斯 · 哈萨比斯与他们的团队开发的 AlphaGo 战胜了世界围棋冠军、职业九段选手李世石,并以 4:1 的总比分获胜。
- 深度学习的技术突破:生成对抗、注意力机制、预训练模型
DL在AI的成功应用
语音识别
2009年, Hinton把深层神经网络介绍给做语音识别的学者们。2010年,语音识别就产生了巨大突破。本质上是把传统的混合高斯模型(GMM)替换成了
深度神经网络(DNN)模型,但相对识别错误率一下降低20%多,这个改进幅度超过了过去很多年的总和。这里的关键是把原来模型中通过 GMM 建模的手工特征换成了通过 DNN 进行更加复杂的特征学习。
在此之后,在深度学习框架下,人们还在不断利用更好的模型和更多的训练数据进一步改进结果。现在语音识别已经真正变得比较成熟,并且被广泛商用,目前所有的商用语音识别算法没有一个不是基于深度学习的。
计算视觉:通过组合低层特征形成更加抽象的高层特征
DL在图像识别
Yann LeCun早在1989年就开始了卷积神经网络的研究,取得了在一些小规模(手写字)的图像识别的成果,但在像素丰富的图片上迟迟没有突破,直到2012年Hinton和他学生在ImageNet上的突破,使识别精度提高了一大步;截至2015年最好的模型ResNet
2012年 Google Brain 用 16000 个 CPU 核的计算平台训练 10 亿神经元的深度网络,无外界干涉下自动识别了“Cat”
2014年香港中文大学教授汤晓鸥研究组DeepID的深度学习模型,在 LFW 数据库上获得了99.15%的识别率,人用肉眼在LFW上的识别率为97.52%,深度学习在学术研究层面上已经超过了人用肉眼的识别 。
自然语言处理
词向量表示学习
词向量是指通过对大量文本的无监督学习,根据前后文自动学习到每个词的紧凑向量表达,包括NNML 、 Word2Vector 、预训练模型等。
预训练模型:ELMo、 GPT和BERT 等,全线提升自然语言领域的多项任务的Baseline
递归神经网络 RNN:文本的各个词之间是有顺序的,RNN能更好的挖掘和利用这个性质,在自然语言各个领域都在尝试进行中。 已经有BPTT 、 LSTM等。
神经网络模型概述
神经网络模型学习框架
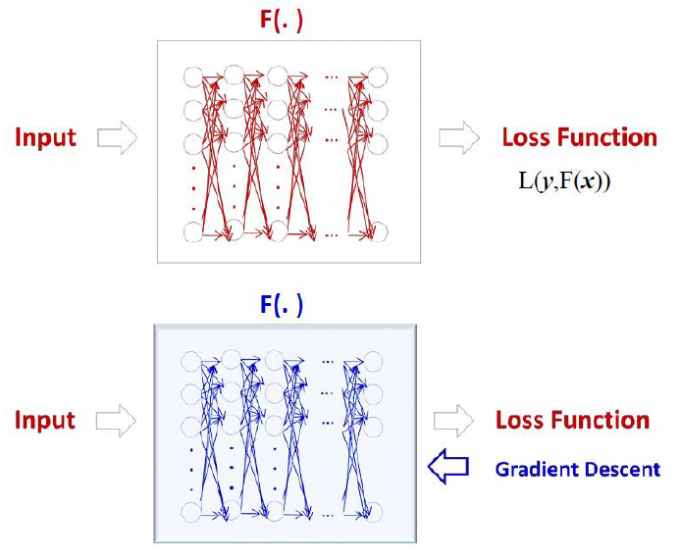
损失函数:
平方损失:
交叉熵损失:
单个神经元模型:
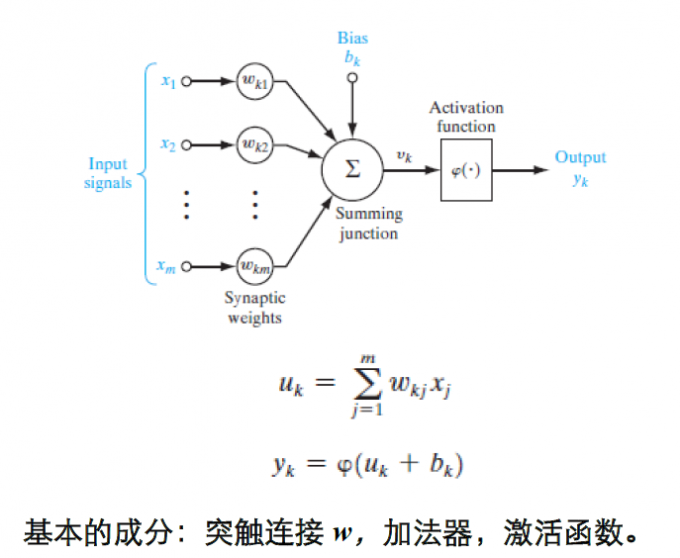
单个神经元模型:
- 感知机
- 最小方差回归
- Logistic模型
多层感知机
卷积网络
核函数网络:单隐层神经网络、非线性体现在径向基核函数
- 径向基网络
- 支持向量机
自组织映射
RBM
- 同层神经元间无连接,并彼此相互独立
- 是一个无向图(权值对称),即连接可看作双向的
层为隐层,
层为可见层
递归网络
深度网络模型概述
深度前馈网络
常见的结构:
- 全连接网络DFL
- 预训练+全连接网络 Au+FL
- 卷积+全连接网络 CNN+FL
- CNN + FL+ ReLu + Tricks
递归神经网络
常见的结构:
- Bi结构
- Deep结构
- CNN+RNN结构
生成对抗网络(GAN)
两个网络博弈:G(Generator)和D(Discriminator)
- G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
- D是一个判别网络,判别一张图片是不是“真实的”。它输入一张图片x,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
深度强化学习
强化学习:学习目标:策略概率
值函数网络:Deep Q-Learning
策略网络:Deep Policy Network
多层感知机
含有数据输入层、1个以上隐藏层、 1个输出层;各层神经元全连接,同一层神经元之间无连接。
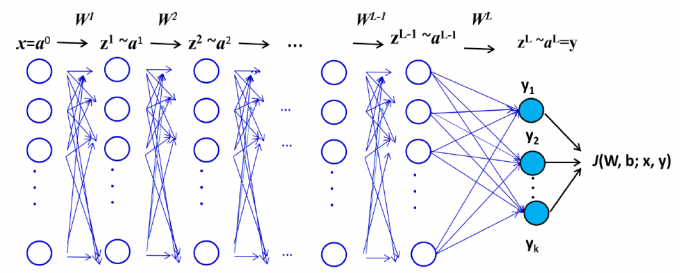
多层感知机的运算:

激活函数(包括硬门限阈值函数),是导致网络运算非线性的直接原因。
问题描述
学习问题:
学习目标:调整神经元连接权重值,使得平均误差能量最小。
两种方法:批量学习和在线学习。
目标:最小化损失函数
批量学习(Batch Learning)
- N个样本(一个batch)
- 随机采样 batch 训练样本集
- Batch by Batch 调整权值
- 优点:梯度向量形式固定,有利于并行处理
- 缺点:需要内存资源大
在线学习(Online Learning):sample by sample 调整权值
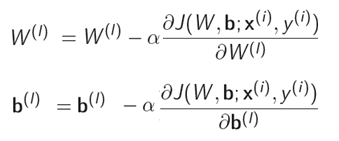
优点:容易执行、存储量小、有效解决大规模和困难模式的分类。
缺点:学习过程随机、不稳定。
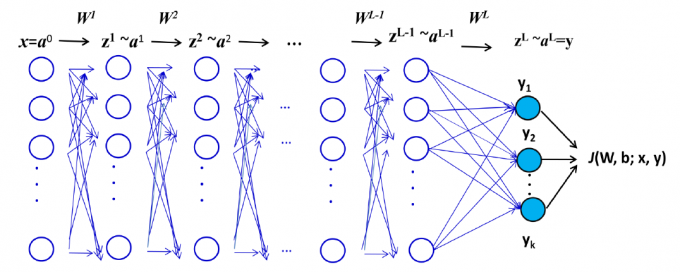
BP基本思想
两个方向的信号流、两个方向的函数运算
函数信号:计算输出函数信号
误差信号:计算梯度向量
数据前馈运算
梯度反馈运算
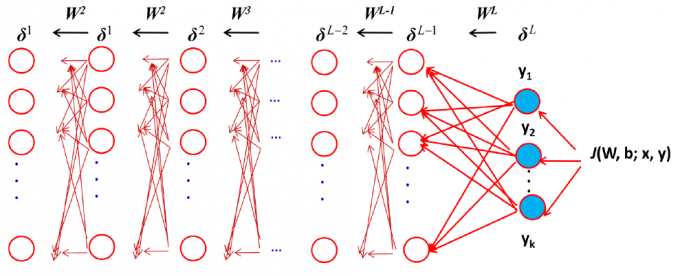
BP 算法小结
- 数据初始化
- Epoch 采样
- 前向计算
- 反向梯度计算
- 求参数梯度
- 迭代
激活函数
异或问题
改善性能的试探法
函数逼近
卷积网络
卷积层:卷积层具有局部连接和权重共享特点。
一维、二维卷积
卷积层的输出尺度
卷积层的参数个数
子采样层:每个通道,通过下采样,缩减尺度。
典型实例:LeNet-5
Recurrent 网络
四种基本递归结构
- 输入-输出递归模型(NARX 模型)
- 状态空间模型
- 递归多层感知机
- 二阶网络
通用逼近定理:如果网络具有充分多的隐藏神经元,任意的非线性动态系统可以由递归神经网络以期望的精度来逼近,对于状态空间的紧致性没有限制。
计算能力
Recurrent 网络
RNN分回合训练
RNN连续训练
RNN长期依赖
RNN扩展的递归结构
前沿概述
深度学习
深层结构:神经网络 + 深层结构 + 优化 + 计算资源 + 人工智能应用
梯度消失:解决梯度消失
- 前馈网络:自编码、ReLU 激活函数
- Recurrent 网络:二次优化、非线性逐次状态估计、ReLU 激活函数
视觉识别
自然语言处理
生成对抗学习
生成对抗模型原理
生成器(Generator):尽可能去学习真实样本的分布,迷惑鉴别器。
鉴别器(Discriminator):尽可能的正确判断输入数据是来自真实数据还是来自生成器。
损失函数:
训练过程:生成器与鉴别器交替训练,互相提升各自的生成能力和鉴别能力,最终寻找二者之间的一个纳什均衡。
强化学习
马尔科夫决策过程:
智能体环境交互-智能体的目标是最大化将来的期望累积奖励
知识图谱
背景
知识图谱的概念最早出现于Google公司的知识图谱项目,体现在使用Google搜索引擎时,出现于搜索结果右侧的相关知识展示。
截止到2016 年底,Google知识图谱中的知识数量已经达到了600亿条,关于1500个类别的5.7亿个实体,以及它们之间的3.5万种关系。
实体、关系和事实:
- 实体(entity):现实世界中可区分、可识别的事物或概念。
- 关系(relation):实体和实体之间的语义关联。
- 事实(fact): (head entity, relation, tail entity) 三元组形式。
狭义知识图谱
狭义知识图谱:具有图结构的三元组知识库。
节点:实体。 边:事实(由头实体指向尾实体)。 边的类型:关系。
链接预测、三元组分类:知识图谱上的链接预测
分布式知识表示方法分类:
- 位移距离模型 (translational distance models):采用基于距离的打分函数来衡量三元组成立的可能性。
- 语义匹配模型 (semantic matching models):采用基于相似度的打分函数来衡量三元组成立的可能性。
- 简单匹配模型:RESCAL及其变种-将头实体和尾实体的表示进行组合后再与关系的表示进行匹配
- 复杂匹配模型:深度神经网络-利用较为复杂的神经网络结构完成实体和关系的语义匹配