MIT-6.824 Distributed Systems-Lab 2 Raft
MIT-6.824(Spring 2022)Lab 2 Raft
简介
这是构建容错k/v存储系统的一系列实验室中的第一个。这个实验室将实现复制状态机协议Raft。
复制服务通过在多个副本服务器上存储其状态(即数据)的完整副本来实现容错。复制允许服务继续运行,即使某些服务器出现故障(崩溃或网络问题)。挑战在于,故障可能会导致复制副本保存不同的数据副本。
Raft将客户端请求组织成一个序列,称为日志,并确保所有副本服务器都看到相同的日志。每个副本按日志顺序执行客户端请求,并将它们应用于服务状态的本地副本。由于所有活动副本都看到相同的日志内容,因此它们都以相同的顺序执行相同的请求,从而继续具有相同的服务状态。如果服务器出现故障,但稍后恢复,Raft会负责更新其日志。只要有大多数服务器处于活动状态,并且可以相互通信,Raft就会继续运行。如果没有这样的大多数,Raft将会暂时停机,但一旦大多数服务器能够再次通信,Raft就会恢复原来的状态。
在这个实验中,将会把Raft实现为一个Go对象类型,并实现相关的方法,这意味着要在更大的服务中将Raft用作模块。一组Raft实例通过RPC相互通信,以维护复制的日志。Raft接口将支持无限序列的编号命令,也称为日志条目。条目用索引编号进行编号。具有给定索引的日志条目最终会被提交。此时,Raft应该将日志条目发送到更大的服务以供其执行。
您应该遵循扩展的Raft论文中的设计,尤其是图2。您将实现本文中的大部分内容,包括保存持久状态,并在节点发生故障后重新启动后读取该状态。不实现第6节提到的集群成员资格更改。
最具挑战性的部分可能不是实现解决方案,而是调试解决方案。为了帮助解决这一挑战,您可能需要花时间思考如何使实现更易于调试。
我们还提供了一个Raft交互的图表,可以帮助阐明Raft代码如何与上面的层进行交互。
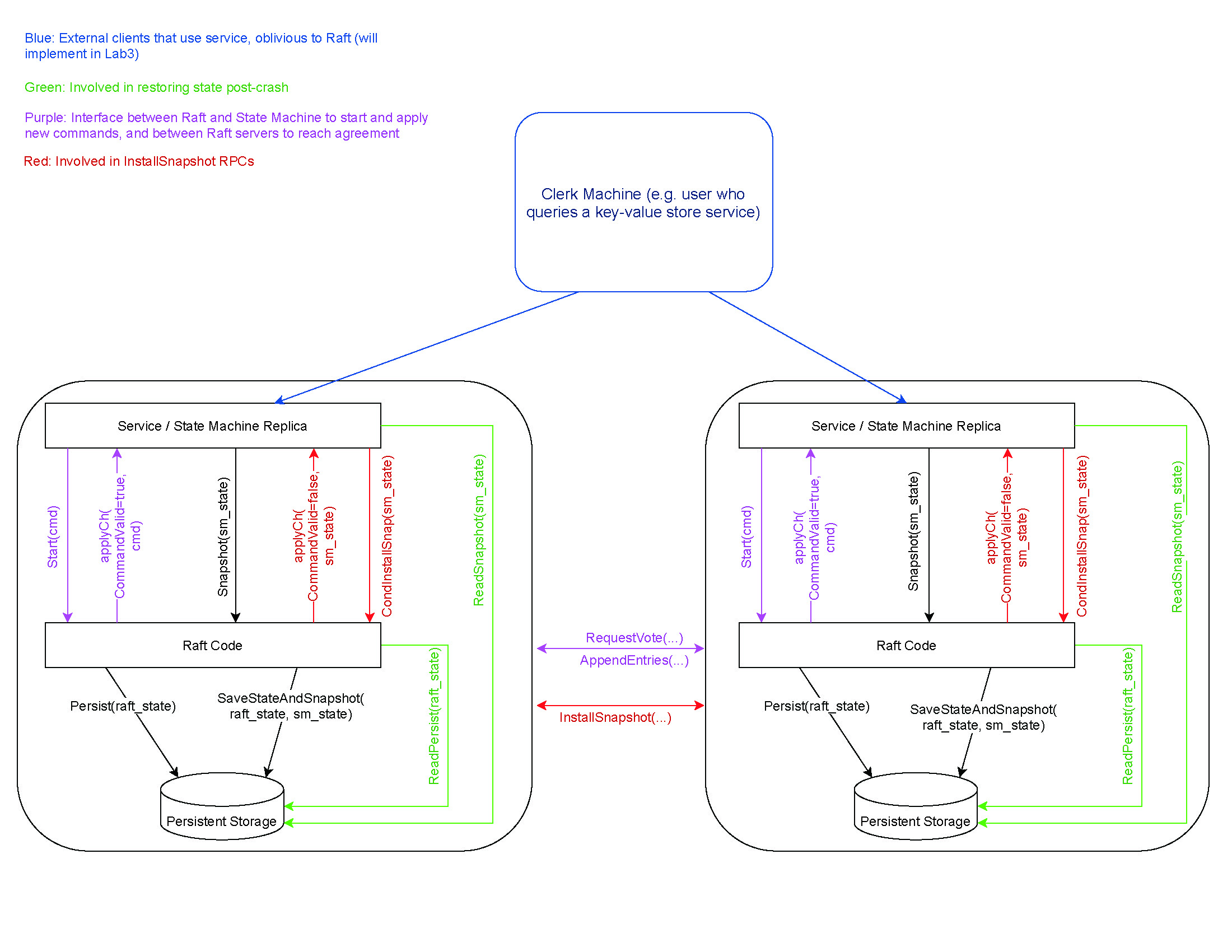
参考资料
Students' Guide to Raft
(几年前编写,特别是2D部分已经发生了变化)
背景
Raft 是一种共识算法,旨在轻松理解。它与Paxos的容错和性能相当。不同的是,它被分解成相对独立的子问题,它干净地解决了所有主要部分的实际系统需求。我们希望Raft可供更广泛的受众使用,并且这些更广泛的受众将是能够开发各种更高质量的基于共识的系统。
与所有分布式共识协议一样,细节很难理解。在没有故障的稳定状态下,Raft 的行为易于理解,并且可以直观地解释。例如,从可视化中很容易看出, 假设没有失败,最终将选出Leader,并且最终,发送给Leader的所有操作都将由Follower按照顺序正确执行。但是,当消息延迟,网络分区或者服务故障,细节变得至关重要。特别是,我们可能一遍又一遍地重复许多错误,仅仅是由于阅读论文时的误解或疏忽。这个问题并非Raft所独有。
实现Raft
Raft 的最终指南在 Raft 论文的图 2 中。这个图片指定在Raft服务器之间交换的每个RPC的行为, 给出服务器必须维护的各种不变量,并指定何时应执行某些操作。我们将在本文的其余部分大量讨论图 2。它需要一字不差地遵循。
图 2 定义了每个服务器在各种状态下应该对每个传入的 RPC应该做什么,以及何时发生某些其他事情(例如就像在日志中应用条目是安全的一样)。图 2 非常精确,每一条语句在规范术语中,它应该被视为必须,而不是应该。例如,您可以合理地重置一台服务器的选举计时器,只要您收到或RPC,都表明其他服务器要么认为它是Leader,或者是努力成为Leader。直觉上,这意味着我们不应该干扰。但是,如果您仔细阅读图 2,它会说:如果选举超时过去而没有收到当前Leader的RPC或投票给其他的服务器,则转换为Candidate。
事实证明,区别很重要,因为前一种实现在某些情况下,可能导致活性显著降低。
细节的重要性
考虑一个例子。Raft论文在许多地方提到了心跳RPC。具体来说,领导者将偶尔(每个检测信号间隔至少一次)向所有服务器发送 RPC,以防止它们启动新的选举。如果领导者没有要发送到特定对等方的新条目, RPC 不包含任何条目,被视为心跳。
我们的许多学生认为心跳在某种程度上是“特别的”,当服务器收到心跳时,它应该以不同的方式对待它。特别是,许多人会只在收到心跳时重置他们的选举计时器,然后返回成功,而不执行图2中指定的任何检查。这是极其危险的。通过接受 RPC, Follower隐式地告诉Leader他们的日志与Leader匹配并包括参数中包含的内容。收到回复后,领导可能错误地确定某个条目已被复制到大多数服务器,并开始提交它。
许多人遇到的另一个问题是在收到心跳时,他们会截断Follower的记录,然后添加参数中包含的日志条目。这也是不正确的。图 2说明,如果现有条目与新条目冲突(相同的索引但 不同的任期),删除现有条目及其后面的所有条目。
这里的如果至关重要。如果Follower拥有Leader的所有条目,Follower不得截断其日志。必须保留Leader发送的条目之后的任何元素。这是因为我们可能从Leader收到过期的RPC,截断日志将意味着“收回”我们可能已经告诉Leader的我们的日志。
调试Raft
在调试时,Raft通常有四个主要的错误来源: 活锁、不正确或不完整的 RPC 处理程序、未能遵循规则和术语混淆。死锁也是一个常见问题,但它们通常可以通过记录所有锁和解锁来调试,并且弄清楚你正在占有哪些锁且没有释放。
活锁
当系统活锁时,系统中的每个节点都在执行一些东西,但总的来说,你的节点没有取得进展。一个活锁场景特别频繁出现:没有领导人被选举出来,或者一个领导者被选举出来后另一个节点马上开始选举,迫使最近当选的领导人立即退位。
出现这种情况的原因有很多:
确保在图 2说明的时候准确重置选举计时器。具体来说,有三种情况:
- 从当前Leader那里获得 RPC (如果参数中的任期已过时,则不应重置计时器)
- 正在开始选举
- 向其他服务器投票。
最后一种情况在不可靠的网络中尤其重要,其中Follower可能有不同的日志,在这些情况下, 只有少量的服务器使得大多数服务器都愿意投票支持。如果每当有人要求您投票给他们时都重置选举计时器,会使日志过时的服务器同样有可能向前迈进
事实上,因为很少的服务器有足够的最新的日志,这些服务器不太可能在足够和平的情况下进行选举。如果您遵循图 2,具有最新日志的服务器不会被过时的服务器选举打断,因此更有可能完成选举并成为Leader。
按照图 2 的说明操作了解何时应开始选举。 特别要注意的是,如果您是Candidate,但选举计时器触发,应该开始另一次选举。这对于避免由于 RPC 延迟或丢弃而导致系统停止非常重要。
在处理传入的 RPC 之前 ,请确保遵循“服务器规则”中的第二条规则。第二条规则规定:如果 RPC 请求或响应包含术语set ,则转换为Follower
例如,如果您已经在当前任期内投票,并且传入的RPC有一个更高的任期号,你应该首先下台并采用他们的任期(从而重置),然后处理RPC,处理的过程中就会进行投票
不正确的 RPC 处理程序
尽管图 2 准确地说明了每个 RPC 处理程序应该执行的操作, 一些细节仍然很容易被忽略。
如果步骤显示“回复错误”,这意味着您应该立即回复,不要执行任何后续步骤。
如果你得到一个指向日志末尾的RPC,应该像确实有该条目,但该任期不匹配处理这个。
如果领导者没有发送任何条目,RPC处理程序的检查 2 应执行。
#5 是必要的, 并且需要使用最后一个新条目的索引进行计算。 这是因为日志中可能存在与领导者日志不同的条目。因为 #3 规定您只有在有冲突的条目情况下才会截断日志,这些条目不会被删除,如果超出领导发送给您的条目,您可能会应用不正确的条目。
实施“最新日志”检查非常重要。只是检查长度!
不遵守规则
虽然 Raft 论文非常明确地说明了如何实现每个 RPC 处理程序,它还留下了许多规则的实现和未指定的不变量。这些列在“服务器规则”中 图 2 右侧的块。虽然其中一些是不言自明的,也有一些需要非常小心地设计,以免违反规则:
如果在执行过程中的任何时候应用特定的日志条目。请务必确保仅由一个实体完成此应用程序。具体来说,您需要有一个专门的 “应用器”,或者锁定这些应用,以便其他一些例程不会同时检测到需要应用条目。
确保定期更新,或更新后进行检查。例如,如果您在发送给同行的同时进行检查,您可能需要等到下一个条目追加到日志中后再应用您刚刚发送并得到确认的条目。
如果领导者发出 RPC,并且被拒绝,但不是因为日志不一致(这只有在我们的任期中才会发生),那么您应该立即下台并且不更新。
领导者不允许更新到上一任期(或就此而言,未来任期)的某个地方。因此特别需要检查。这是因为如果这不是他们目前的任期,Raft 领导者无法确定条目是否实际提交(并且将来永远不会更改)。
一个常见的问题来源是nextIndex和matchIndex之间的区别。特别是,你可能会观察到matchIndex = nextIndex - 1,而干脆不实现matchIndex。这是不安全的。虽然nextIndex和matchIndex通常在同一时间被更新为类似的值(具体来说,nextIndex = matchIndex + 1),但两者的作用完全不同。它通常是相当乐观的(我们分享一切),并且只在消极的反应中向后移动。例如,当一个领导者刚刚当选时,nextIndex被设置为日志末尾的索引指数。在某种程度上,nextIndex是用于性能的–你只需要将这些东西发送给这个对等体。
matchIndex是用于安全的。MatchIndex不能被设置为一个太高的值,因为这可能会导致commitIndex被向前移动得太远。这就是为什么matchIndex被初始化为-1(也就是说,我们不同意任何前缀),并且只在跟随者肯定地确认AppendEntries RPC时才更新。
任期混淆
任期混淆是指服务器被来自旧任期的RPC所迷惑。一般来说,在收到RPC时,这不是一个问题,因为图2中的规则确切地说明了当你看到一个旧任期时你应该做什么。然而,图2一般没有讨论当你收到旧的RPC回复时你应该做什么。根据经验,我们发现到目前为止,最简单的做法是首先记录回复中的任期(它可能比你当前的任期高),然后将当前任期与你在原始RPC中发送的任期进行比较。如果两者不同,就放弃回复并返回。只有当这两个任期相同时,你才应该继续处理回复。
一个相关但不完全相同的问题是,预设你的状态在你发送RPC和你收到回复之间没有变化。这方面的一个很好的例子是,当你收到RPC的响应时,设置matchIndex = nextIndex - 1,或者matchIndex = len(log)。这并不安全,因为这两个值都可能在你发送RPC后被更新。相反,正确的做法是将 matchIndex 更新为你最初在 RPC 中发送的参数中 prevLogIndex + len( entries[]) 。
Raft的结构
一个Raft实例必须处理外部事件的到来(Start()调用、AppendEntries和RequestVote RPC以及RPC回复),它必须执行定期任务(选举和心跳)。有许多方法可以构造Raft代码来管理这些活动,下面是一些想法。
- 每个Raft实例都有一组状态(日志、当前索引、&c) 必须根据在goroutine并行同时发生的事件进行更新。Go文档指出,goroutine可以使用共享数据结构和锁直接执行更新操作,或者通过在channel上传递消息。经验表明,对于Raft使用共享数据和锁是最简单的。
- Raft实例有两个时间驱动的活动:Leader必须发送心跳信号,如果距离上一次接收到心跳信号的时间太长,其他人必须开始选举。每一个活动最好单独启动一个专门的长时间运行的goroutine,而不是将多个活动组合成一个单独的goroutine
- 选举超时的管理是很头痛的。最简单的方法是在Raft数据结构中包括上一次Follower接收到Leader消息的时间,然后让负责选举的goroutine定期检查这个时间是否超时。使用time.Sleep()和一个小常量参数驱动定期检查是很容易的。不要使用time.Ticker和time.Timer,它们很难正确使用。
- 需要有一个单独的长时间运行的goroutine在applyCh上按顺序提交日志条目。它必须是单独的,因为在applyCh上发送可以被阻止;而且必须是单个
goroutine,否则很难确保发送日志是按照日志顺序的。advance commitIndex的代码需要kick apply goroutine;使用sync.Cond可能最简单。 - 每个RPC应该以自己的方式发送(并处理其回复)自己的goroutine,原因有两个:这样无法访问的服务器不会延迟大多数回复的收集,而且心跳信号和
选举计时器可以一直计时。如果RPC应答处理在同一个goroutine中就很容易做到,而不是通过channel发送回复的信息。 - 请记住,网络可能会延迟RPC和RPC响应,而且如果发送并行的RPC,网络可以对请求和答复进行重新排序。图2很好地指出了RPC处理程序必须对此小心(例如,RPC处理程序应该忽略具有旧日志条目的RPC)。图2并不总是明确说明RPC响应的处理过程。Leader在处理RPC响应时必须小心,它必须检查自从发送RPC之后日志条目没有改变,并且必须考虑对同一Follower的并发的RPC改变了Leader的状态(例如nextIndex)。
Raft中的锁
- 当有多个goroutine使用的数据时,且至少有一个goroutine可以修改数据,那么goroutine应该使用锁防止同时使用数据。Go race检测器非常擅长检测违反此规则的情况。
- 每当代码对共享数据进行一系列修改时,如果其他goroutine查看了数据,可能会出错,因此在整个过程中都应该使用锁。
- 每当代码对共享数据进行一系列读取时(或读取和写入),如果另一个goroutine在中途修改数据,则会发生错误。因此在整个过程中都应该使用锁。真正的Raft代码需要使用很长代码的锁,例如,一个Raft RPC处理程序可能需要在整个处理过程都要加锁。
- 在做一些可能会等待的事情的时候都加锁是个坏主意,例如:读取Go channel,在channel上发送,等待计时器、调用time.Sleep()或发送RPC并等待回复。一个原因是你可能想让其他的goroutine在等待期间照常执行。另一个原因是避免死锁。想象两个服务器在保持锁的同时彼此发送RPC;两个RPC
处理程序需要接收对方的锁;两个RPC处理程序都不能完成,因为它需要等待的RPC调用所持有的锁。等待的代码应该首先释放锁。如果这不方便,有时创建一个单独的goroutine来执行等待是很有用的。 - 要小心扔掉和重新获取锁的情况。一个可能出现这种情况的地方是避免带锁等待。例如,下面的发送投票RPC的代码是不正确的:
rf.mu.Lock()
rf.currentTerm += 1
rf.state = Candidate
for <each peer> {
go func() {
rf.mu.Lock()
args.Term = rf.currentTerm
rf.mu.Unlock()
Call("Raft.RequestVote", &args, ...)
// handle the reply...
} ()
}
rf.mu.Unlock()这个代码在单独的goroutine中发送每个RPC。这是不正确的,因为如果周围的代码是决定成为Candidate,args.Term可能与rf.currentTerm不同。当周围的代码创建goroutine和当goroutine读取rf.currentTerm时可能过去了很多的时间,这台服务器也可能不再是Candidate。一种方法是当外部代码持有锁的时候创建rf.currentTerm的副本从而让goroutine去使用。同样的,在调用之后的回复处理代码重新获取锁后必须重新检查所有相关的假设,例如,它应该检查自从决定成为Candidate后rf.currentTerm没有再次改变。
一种方法是从没有锁的代码开始,然后仔细考虑需要在哪里添加锁以变得正确。另一个更务实的方法从观察开始,如果没有并发性(没有同时执行goroutine)则根本不需要锁。但是当RPC系统创建goroutine以执行RPC处理程序时,以及
因为您需要在单独的goroutine中发送RPC以避免等待,并发性就有了。可以通过识别所有goroutine开始的位置(RPC处理程序、在Make()中创建的后台goroutine,&c),并且在每个goroutine开始的时候获得锁,只有当goroutine
完全完成并返回的时候才释放锁,从而消除并发性。这个锁定协议确保任何重要的事情都不会并行执行;锁确保每个goroutine在其他goroutine执行之前完成,没有并行执行,很难违反规则1、2、3或5。如果每个goroutine的代码正确,在使用锁抑制并发时仍然是正确的。
然而,规则4可能是一个问题。所以下一步是找到代码等待的位置,然后根据需求添加锁释放和重新获取(或goroutine的创建),记得小心重新建立和重新获取后的情况。
代码相关
框架代码:src/raft/raft.go
测试代码:src/raft/test_test.go,运行go test即可
通过在src/raft/raft.go中增加代码实现Raft,必须遵循下面的接口:
// create a new Raft server instance:
rf := Make(peers, me, persister, applyCh)
// start agreement on a new log entry:
rf.Start(command interface{}) (index, term, isleader)
// ask a Raft for its current term, and whether it thinks it is leader
rf.GetState() (term, isLeader)
// each time a new entry is committed to the log, each Raft peer
// should send an ApplyMsg to the service (or tester).
type ApplyMsg服务调用 Make(peers, me, ...)创建一个 Raft peer。peers 参数是所有 Raft peers(包括这一个)的网络标识符数组,用于 RPC。me参数是网络标识符数组中,属于这个peer的网络标识符的下标。Start(command) 要求 Raft 启动处理,将命令追加到日志副本中。Start()应立即返回,无需等待日志追加完成。该服务希望你将每个新的日志条目,封装为 ApplyMsg,发送给Make函数中的 applyCh参数(这是一个channel)。
raft.go包含发送 RPC sendRequestVote()和处理传入 RPC RequestVote()的样例代码。您的 Raft peers 应该使用 labrpc Go 包(源代码在 src/labrpc)交换 RPC。测试代码可以告诉 labrpc 延迟 RPC请求,重新排列它们,并丢弃它们以模拟各种网络故障。Raft 实例必须仅与 RPC 交互;例如,不允许它们使用共享的 Go 变量或文件进行通信。
后续的实验也在此实验上进行构建。
参考翻译:https://zhuanlan.zhihu.com/p/248686289
Part 2A:选举Leader
指导
实现Raft算法中的Leader选举和心跳机制(AppendEntries RPC 且没有日志条目)。确保只有一个Leader被选中,且若无错误该Leader会一直唯一存在,当该Leader下线或发生其他错误导致发出的数据无法被成功接收,则会产生新的Leader来替代。
- 运行
go test -run 2A来验证代码的正确性 - 参考论文的Figure 2实现,需要关注发送和接收RequestVote RPCs,与选举相关的服务器的规则,和与选举相关的服务器的状态
- 在
raft.go中添加Figure 2的Leader选举的状态,同时也需要定义一个结构体保留日志条目的信息 - 填充
RequestVoteArgs和RequestVoteReply结构。修改Make()以创建一个后台 go 协程,该协程将在一段时间未从其他 peers 那里听到请求投票 RPC 时,发送RequestVoteRPC 来定期启动 Leader 选举。这样,如果已经有一个 Leader,或者自己成为 Leader,其他 peers 就会知道谁是Leader。实现RequestVote()RPC 函数,以便服务器投票给别人。 - 为了实现心跳检测,请提前定义
AppendEntriesRPC 结构(尽管您可能还不需要所有参数),并让 Leader 定期发送它们。AppendEntriesRPC 函数需要重置选举超时时间,以便其他服务器已当选时,不会以 Leader 的身份继续运行。 - 确保不同 Peers 不会在同一时间选举超时,否则所有 Peers 将只为自己投票,没有人会成为 Leader。
- 测试要求 Leader 发送心跳检测 RPC 的频率不超过 10 次/秒。
- 测试要求您的 Raft 在旧 Leader 失败后5秒内选出新 Leader(如果大多数同行仍然可以沟通)。但是,请记住,在发生分裂投票的情况下(如果数据包丢失或候选人不幸地选择相同的随机回票时间,则可能发生),领导人选举可能需要多轮投票。您必须选择足够短的选举超时(心跳间隔也是如此),确保即使选举需要多次轮断,也能在5秒内完成。
- 论文第 5.2 节提到选举超时应该在 150 到 300 毫秒范围内。只有当 Leader 发送一次心跳包的远小于 150 毫秒,这种范围才有意义。由于测试将您发送心跳包的频率限制在 10 次/秒内(译者注:也就是大于 100 毫秒),因此您必须使用比论文 150 到 300 毫秒更大的选举超时时间,但请不要太大,因为那可能导致无法在 5 秒内选出 Leader。
- Go 的 rand 很有用。
- 您将需要定期执行某些操作,或在一段时间后做些什么。最简单的方法是新起一个协程,在协程的循环中调用time.Sleep()。不要使用
time.Timer或time.Ticker,这两个并不好用,容易出错。 - 如果代码在通过测试时遇到问题,请再次阅读论文的 Figure 2 ;Leader 选举的逻辑分布在Figure 2 的多个部分。
- 别忘了实现
GetState()。 - 测试调用您的 Raft 的
rf.Kill()时,您可以先调用rf.killed()再检查是否Kill()。您可能希望在所有循环中执行此功能,以避免已经死亡的 Raft 实例打印令人困惑的信息。 - 调试代码的一个好方法,就是在 Peer 发送或收到消息时打印自己的状态,并在测试时运行
go test -run 2A > out,将日志收集到文件中。然后,通过研究out文件,可以确定实现中不正确的地方。您可能会喜欢用util.go中的Dprintf函数来调试,其可以在不同情况下打开和关闭日志。 - Go RPC 仅发送以大写字母为首的结构体字段(译者注:可导出的字段)。子结构体还必须具有大写字段名称(例如数组中的日志记录字段)。
labgob包会警告您这一点,不要忽略警告。 - 用
go test -race测试你的代码,并修复它报告的任何问题。
输出应该如下面所示:
$ go test -run 2A
Test (2A): initial election ...
... Passed -- 3.5 3 58 16840 0
Test (2A): election after network failure ...
... Passed -- 5.4 3 118 25269 0
Test (2A): multiple elections ...
... Passed -- 7.3 7 624 138014 0
PASS
ok 6.824/raft 16.265s
$每一个“通过”的测试用例会输出五个数字;他们分别是
- 测试所用的时间(单位:秒)
- Raft Peer 的数量(通常为 3 或 5)
- 测试期间发送 RPC 的次数
- RPC 消息中的字节总数
- Raft 确定并提交的日志条目数。
实现
定义 global.go
首先需要对代码中不完整的结构体进行填充,论文中的Figure 2有的字段一定保留,其他的字段看情况保留
首先定义服务器的状态,用字符串常量表示:
// 定义Peer的状态
type State string
const (
Follower State = "follower"
Candidate State = "candidate"
Leader State = "leader"
)然后定义Raft结构体:
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
// 在所有peer上面的持久性的状态
// 在对RPC进行响应之后要在稳定存储上更新
currentTerm int // this peer 看到的最新的任期号
votedFor int // 在当前任期获得选票的Candidate的id(如果没有则为-1)
log []LogEntry // 日志信息
// 在所有peer上面的变化的状态
commitIndex int // 已知的已经被提交的日志条目的最大索引值
lastApplied int // 最后被应用到状态机的日志条目索引值(初始化为 0,持续递增)
// 在Leader上面的变化的状态
// 每一次选举后都要重新进行初始化
nextIndex []int // 对于每⼀个服务器,需要发送给他的下⼀个日志条目的索引值(初始化为Leader最后索引值加1)
matchIndex []int // 对于每⼀个服务器,已经复制给他的日志的最高索引值
// 与时间相关的变量
electTimeout int64 // 选举超时时间
randomTimeout int64 // 随机时间
heartBeatTimeout int64 // 心跳周期
// 当前状态
state State // 当前Peer所处的状态(Leader、Candidate或Follower)
majorityVote int // 成为Leader需要获得的最少票数
lastReceive int64
}其中多定义了6个变量,3个变量与时间相关,分别表示选举超时时间、随机的时间上限和Leader发送心跳的周期时间
// 与时间相关的变量
electTimeout int64 // 选举超时时间
randomTimeout int64 // 随机时间
heartBeatTimeout int64 // 心跳周期最后3个变量,第1个表示服务器当前所处的状态,第2个表示成为Leader需要获得的最少票数,这个值提前计算出来,最后一个值表示最后一次接收到Leader的心跳信号的时间
// 当前状态
state State // 当前Peer所处的状态(Leader、Candidate或Follower)
majorityVote int // 成为Leader需要获得的最少票数
lastReceive int64 // 最后一次接收到Leader的心跳信号的时间工具 util.go
服务器不同状态之间的转换比较频繁,因此可以将这些服务器状态转换的代码提取出来编写成工具函数,方便后续直接调用
// 转为Leader
func (rf *Raft) toLeader() {
DPrintf("[%d]: convert from [%s] to [%s], term [%d]", rf.me, rf.state, Leader, rf.currentTerm)
rf.state = Leader
// rf.lastReceive = time.Now().Unix()
}
// 转为Follower
func (rf *Raft) toFollower(newTerm int) {
DPrintf("[%d]: convert from [%s] to [%s]", rf.me, rf.state, Follower)
rf.state = Follower
rf.currentTerm = newTerm
rf.votedFor = -1
rf.lastReceive = time.Now().Unix()
}
// 转为Candidate
func (rf *Raft) toCandidate() {
DPrintf("[%d]: convert from [%s] to [%s]", rf.me, rf.state, Candidate)
rf.state = Candidate
rf.currentTerm += 1
rf.votedFor = rf.me
// rf.lastReceive = time.Now().Unix()
}- 转为Leader只需更新自己的状态即可,不需要对其他值做任何的操作。
- 转为Follower除更新自己的状态之外,要更新自己的任期(因为变为Follower就是因为自己的任期落后),然后要初始化自己的投票状态,并且这个变化的过程隐含了从Leader那里收到心跳包,因此要更新自己的时间。
- 转为Follower除更新自己的状态之外,要将自己的任期+1(因为变为Candidate是因为接收不到Leader的心跳信息了,认为Leader已经挂了,这个任期不能再用了),然后要初始化自己的投票投给自己。
然后补充一个预定义的获取服务器状态的方法
// return currentTerm and whether this server
// believes it is the leader.
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (2A).
rf.mu.Lock()
defer rf.mu.Unlock()
isleader = false
term = rf.currentTerm
if rf.state == Leader {
isleader = true
}
return term, isleader
}请求投票RPC requestVote.go
结构体定义完全按照论文即可,目前不需要其他字段
// example RequestVote RPC arguments structure.
// field names must start with capital letters!
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int // Candidate的任期号
CandidateId int // Candidate的 Id
LastLogIndex int // Candidate最后一条日志条目的索引
LastLogTerm int // Candidate最后一条日志条目的任期
}
// example RequestVote RPC reply structure.
// field names must start with capital letters!
type RequestVoteReply struct {
// Your data here (2A).
Term int // 当前的任期,接收到了之后Candidate可以更新自己
VoteGranted bool // 是否给这个Candidate投票
}核心RPC:
// example RequestVote RPC handler.
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
// RPC 请求不一定在什么时候应用,因此必须加锁
rf.mu.Lock()
defer rf.mu.Unlock()
DPrintf("[%d]: received vote request from [%d]", rf.me, args.CandidateId)
reply.VoteGranted = false
// 如果参数的任期号还没有我的大,不投票,直接默认值返回即可
if args.Term < rf.currentTerm {
// 响应中包含当前自己的任期号
reply.Term = rf.currentTerm
return
}
// 如果参数的任期号比我的大,则我在这个任期内就只能是它的Follower,则更改我的任期号,而且在这个任期内我要投票给它
if args.Term > rf.currentTerm {
rf.toFollower(args.Term)
}
reply.Term = rf.currentTerm // 注意这里任期号已经变化了,因此要重新赋值
DPrintf("[%d]: status: term [%d], state [%s], vote for [%d]", rf.me, rf.currentTerm, rf.state, rf.votedFor)
// 如果参数的任期号和我的相同,则任期号不变,需要通过日志确定是否投票给它
// 这里论文要求的 rf.VotedFor == args.CandidateId 不是很明白
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
// Todo:判断日志是否至少更新才可以投票
rf.votedFor = args.CandidateId
rf.lastReceive = time.Now().Unix() // 更新时间,上面操作相当于与可能的Leader通信过了
reply.VoteGranted = true
DPrintf("[%d]: voted to [%d]", rf.me, args.CandidateId)
}
}核心就是计算返回的reply中的两个值,第一个是是否投票,第二个是当前服务器的任期号。其中任期号一定要小心,可能服务器自己的状态改变后任期号会随之改变,因此一定要及时更新。
- 如果请求我投票的任期号还没有我的大,不投票,直接默认值返回即可
if args.Term < rf.currentTerm {
// 响应中包含当前自己的任期号
reply.Term = rf.currentTerm
return
}- 如果参数的任期号比我的大,则我在这个任期内就只能是它的Follower,则更改我的任期号,而且在这个任期内我要投票给它
if args.Term > rf.currentTerm {
rf.toFollower(args.Term)
}(这个结构不返回,投票的逻辑在下一个结构)
- 如果参数的任期号和我的相同,则任期号不变,需要通过日志确定是否投票给它
rf.votedFor == -1 承接上面的投票逻辑,把情况2的票投了
rf.VotedFor == args.CandidateId 在后面要加上对于日志的判断,这里仅仅是简单投票给它
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
// Todo:判断日志是否至少更新才可以投票
rf.votedFor = args.CandidateId
rf.lastReceive = time.Now().Unix() // 更新时间,上面操作相当于与可能的Leader通信过了
reply.VoteGranted = true
DPrintf("[%d]: voted to [%d]", rf.me, args.CandidateId)
}在调用的时候,Candidate请求每一台服务器投票给它,如果得到的响应说我的任期号比你还大,也就是上面的情况2,也自动放弃Candidate的地位成为Follower。否则这个Candidate就会得到自己的票。
// 向每一个Peer请求投票
func (rf *Raft) requestVoteToPeer(index int, args *RequestVoteArgs, votesSum *int, votesGet *int, cond *sync.Cond) {
reply := RequestVoteReply{}
ok := rf.sendRequestVote(index, args, &reply)
rf.mu.Lock()
defer rf.mu.Unlock()
defer cond.Broadcast()
*votesSum += 1
if !ok {
return
}
if reply.Term > rf.currentTerm {
rf.toFollower(reply.Term)
// } else if reply.VoteGranted && reply.Term == rf.currentTerm {
} else if reply.VoteGranted {
*votesGet += 1
}
}追加日志RPC appendEntries.go
结构体定义完全按照论文即可,目前不需要其他字段
type AppendEntriesArgs struct {
// Your data here (2A, 2B).
Term int // Leader的任期号
LeaderId int // Follower可以通过这个LeaderId重定向客户端
PrevLogIndex int // 新的日志条目紧随之前的索引值
PrevLogTerm int // PrevLogIndex日志条目的任期
Entries []LogEntry // 存储的日志条目,如果是心跳包则为空
LeaderCommit int // Leader的提交索引
}
type AppendEntriesReply struct {
// Your data here (2A).
Term int // 当前的任期,接收到了之后Leader可以更新自己
Success bool // Follower包含了匹配上 prevLogIndex 和 prevLogTerm 的日志时为真
}这个RPC既作为日志更新的来源,在没有日志携带的时候也作为心跳包用于维持Leader的地位
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
// Your code here (2A, 2B).
// RPC 请求不一定在什么时候应用,因此必须加锁
rf.mu.Lock()
defer rf.mu.Unlock()
// 更新至少为当前的任期
reply.Term = rf.currentTerm
reply.Success = false
// 如果Leader的任期还没有我的大,则直接拒绝请求
if args.Term < rf.currentTerm {
return
}
// 如果Leader的任期比我的大,则我转为这个任期的Follower
if args.Term >= rf.currentTerm || rf.state == Candidate {
rf.toFollower(args.Term)
}
// 如果Leader的任期和我的相同,则操作日志
// Todo:日志操作
rf.lastReceive = time.Now().Unix()
reply.Term = rf.currentTerm
reply.Success = true
}核心也是计算返回的reply中的两个值,第一个是是否更新成功,第二个是当前服务器的任期号。其中任期号一定要小心,可能服务器自己的状态改变后任期号会随之改变,因此一定要及时更新。
- 如果Leader的任期还没有我的大,则直接拒绝请求
if args.Term < rf.currentTerm {
return
}- 如果Leader的任期比我的大,则如果我是Candidate,放弃Candidate的地位,转为这个任期的Follower
// 如果Leader的任期比我的大,则我转为这个任期的Follower
if args.Term >= rf.currentTerm || rf.state == Candidate {
rf.toFollower(args.Term)
}(同时要对我自己的日志进行更新,目前还没有实现)
- 如果Leader的任期和我的相同,则操作日志(这里没有操作)
- 更新服务器的时间和返回的参数
rf.lastReceive = time.Now().Unix()
reply.Term = rf.currentTerm
reply.Success = true主要是要对服务器的收到Leader的请求的时间进行更新,从而避免Follower转为Candidate,在Leader存在的情况下发起选举
在调用的时候,Leader向其他的每一台服务器发送这个RPC,如果得到的响应说我的任期号比你还大,也就是上面的情况2,也自动放弃Leader的地位成为Follower。
// 向指定的Peer增加日志条目或者发送心跳包
func (rf *Raft) appendEntriesToPeer(index int, args *AppendEntriesArgs) {
reply := AppendEntriesReply{}
if ok := rf.sendAppendEntries(index, args, &reply); ok {
rf.mu.Lock()
defer rf.mu.Unlock()
// Todo:log相关
// 如果响应的任期比Leader更大了,说明Leader需要退位成Follower了
if reply.Term > rf.currentTerm {
rf.toFollower(reply.Term)
}
}
}
主函数 raft.go
初始化
每一台服务器初始化的时候都是一个Follower,任期号为0
除此之外还要设置选举超时时间,心跳发送时间等
以及根据服务器的数量计算好需要多少张选票才能达成共识
然后直接开始选举
rf.toFollower(0)
rf.electTimeout = 200 // 初始化选举超时时间
rf.heartBeatTimeout = 100 // 初始化心跳间隔时间
rf.randomTimeout = 100 // 设置随机时间的最大范围
// 初始化成为Leader需要得到的票数
if len(rf.peers)%2 == 0 {
rf.majorityVote = len(rf.peers)/2 + 1
} else {
rf.majorityVote = (len(rf.peers) + 1) / 2
}
// start ticker goroutine to start elections
go rf.leaderElection()所有的协程都不设置退出条件,因此内部要么是无限循环,要么是有状态变量等进行控制
选举Leader
选举Leader是一个无限循环,在每一次循环的时候记录当前的时间后进行睡眠(固定时间+随机时间),然后在循环内部进行判断,如果上一次循环到这里的实时时间比上一次接收到心跳包的时间还大,说明在睡眠时间内一直没有接收到心跳包,则认为超时,此时就要放弃自己的Follower身份,转为Candidate开始竞选。
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
func (rf *Raft) leaderElection() {
lastElectTime := time.Now().Unix()
for !rf.killed() {
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// time.Sleep().
time.Sleep(time.Duration(rf.electTimeout+rand.Int63n(rf.randomTimeout)) * time.Millisecond)
rf.mu.Lock()
// lastStartTime := startTime
// 如果上一次循环到这里的实时时间比上一次接收到心跳包的时间还大,说明在睡眠时间内一直没有接收到心跳包,则认为超时
if lastElectTime > rf.lastReceive {
//DPrintf("[%d]: current state is [%s].", rf.me, rf.state)
if rf.state != Leader {
DPrintf("[%d]: is not leader, start election.", rf.me)
rf.tryLeader()
}
}
lastElectTime = time.Now().Unix() // 更新“上一次”的时间
rf.mu.Unlock()
}
}然后在 rf.tryLeader()中,首先将服务器的状态转为Candidate,然后构建请求,向其他的peer发送请求投票的RPC,收到响应后对收到的投票进行统计。如果得到了大多数的选票,则这个Candidate可以转为Leader,同时向其他的服务器发送心跳包说明自己已经成为了Leader,其他的peer需要放弃竞选。
func (rf *Raft) tryLeader() {
rf.toCandidate()
votesSum := 1 // 总共的票的数量
votesGet := 1 // 收到的票数,自己首先给自己投票
cond := sync.NewCond(&rf.mu) // 条件变量,控制投票结果的返回
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
}
for i := 0; i < len(rf.peers); i++ {
if i != rf.me {
go rf.requestVoteToPeer(i, &args, &votesSum, &votesGet, cond)
}
}
// 等待票数统计完毕并判断是否能成为Leader
go func() {
rf.mu.Lock()
defer rf.mu.Unlock()
for votesGet < rf.majorityVote && votesSum < len(rf.peers) && rf.state == Candidate {
cond.Wait()
}
if votesGet >= rf.majorityVote && rf.state == Candidate {
rf.toLeader()
// 发送心跳包
go rf.logReplication()
}
}()
}内部的协程同步使用状态变量控制(虽然不明白为什么使用WaitGroup不可以实现功能)
心跳包发送
心跳包发送(或与日志更新一起)是只有Leader才可以发起的动作。
注意定时发起请求即可
// Leader定时发送更新log的请求,同时也作为心跳包
func (rf *Raft) logReplication() {
for !rf.killed() {
rf.mu.Lock()
if rf.state == Leader {
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
}
for i := 0; i < len(rf.peers); i++ {
if i != rf.me {
go rf.appendEntriesToPeer(i, &args)
}
}
}
rf.mu.Unlock()
time.Sleep(time.Duration(rf.heartBeatTimeout) * time.Millisecond)
}
}运行结果
目前最快的结果:
Test (2A): initial election ...
... Passed -- 3.0 3 72 18660 0
Test (2A): election after network failure ...
... Passed -- 4.9 3 166 31952 0
Test (2A): multiple elections ...
... Passed -- 5.3 7 522 111880 0
PASS
ok 6.824/raft 13.335s运行10次后均成功
Part 2B:日志
指导
完善 Leader 和 Follower 的代码,使他们可以追加新的日志条目,并通过 go test -run 2B。
- 你的第一个目标应该是通过
TestBasicAgree2B()。首先实现Start(),然后按照 Figure 2,实现 RPC 函数AppendEntries来收发新的日志条目。通过applyCh发送每一个新提交的日志条目。 - 您需要实现选举限制(论文第 5.4.1 节)。
- 在早期的 2B 实验中,测试中未能达成协议的解决办法是:即使领导人还活着,也举行重复的选举。在选举计时器中找到并修复这个 bug ,或在赢得选举后不要立即发送心跳包。
- 您的代码可能需要循环检测变量。不要让这些循环不间断连续执行,这将使您的服务运行变慢,最终导致测试失败。使用Go的条件变量或在循环中插入
time.Sleep(10 * time.Millisecond)。
如果运行太慢,可能会没法通过接下来的测试。您可以使用 time命令检查您的解决方案使用了多少实时时间和CPU时间。这是典型的输出:
$ time go test -run 2B
Test (2B): basic agreement ...
... Passed -- 0.9 3 16 4572 3
Test (2B): RPC byte count ...
... Passed -- 1.7 3 48 114536 11
Test (2B): agreement after follower reconnects ...
... Passed -- 3.6 3 78 22131 7
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 3.8 5 172 40935 3
Test (2B): concurrent Start()s ...
... Passed -- 1.1 3 24 7379 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 5.1 3 152 37021 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 17.2 5 2080 1587388 102
Test (2B): RPC counts aren't too high ...
... Passed -- 2.2 3 60 20119 12
PASS
ok 6.824/raft 35.557s
real 0m35.899s
user 0m2.556s
sys 0m1.458s
$“ok 6.824/raft 35.557s” 意味着 Go 运行 2B 的测试所用的实时时间为 35.557 秒。“user 0m2.556s” 表示代码运行了 2.556 秒的 CPU 时间,或实际运行(而不是等待或睡眠)所花费的时间。如果测试 2B 使用超过 1 分钟的实时时间,或超过 5 秒的 CPU 时间,则以后的实验可能会遇到麻烦。检查睡眠时间、等待 RPC 超时所花费的时间、没有睡眠或等待地检查条件或channel信息的循环、或发送大量 RPC 的地方。
实现
2A完善 util.go
无论是转为Leader、Follower或者转为Candidate,实际上都可以看成是有一个隐含存在的Leader告诉他们这样做的,因此都要同步更新自己的选举超时时间,防止在有Leader的时候就已经超时,导致Leader的存在时间过短。
// 转为Leader
func (rf *Raft) toLeader() {
DPrintf("[%d]: convert from [%s] to [%s], term [%d]", rf.me, rf.state, Leader, rf.currentTerm)
rf.state = Leader
rf.lastReceive = time.Now().Unix()
// 选举为Leader后重新对所有的peer进行初始化
for i := 0; i < len(rf.peers); i++ {
rf.nextIndex[i] = len(rf.log)
rf.matchIndex[i] = -1
}
}
// 转为Follower
func (rf *Raft) toFollower(newTerm int) {
DPrintf("[%d]: convert from [%s] to [%s]", rf.me, rf.state, Follower)
rf.state = Follower
rf.currentTerm = newTerm
rf.votedFor = -1
rf.lastReceive = time.Now().Unix()
}
// 转为Candidate
func (rf *Raft) toCandidate() {
DPrintf("[%d]: convert from [%s] to [%s]", rf.me, rf.state, Candidate)
rf.state = Candidate
rf.currentTerm += 1
rf.votedFor = rf.me
rf.lastReceive = time.Now().Unix()
}结构体字段理解
首先要注意由于论文中的索引是从1开始计算的,而计算机上切片的索引是从0开始算的,因此论文说明的初始化为0的地方都要初始化为-1
nextIndex[]:leader要发送给follower的下一条log entry(各follower不同),follower与leader一致的时候只发最新一条log,有不一致的时候,nextIndex要减,一次发多条log。把不一致的部分都修正过来。
matchIndex[]:已知follower上,从0开始有多少条连续的log entry与leader一致。即: 有多少条log entry已经被成功replicate到follower上了。如果过半数,就可以增加commitIndex, apply到状态机, 答复客户端操作成功了
commitIndex: 已知被提交的最高日志项对应的index。当日志项被提交(committed)了,意味着该日志项已经成功复制到了集群中的多数派server上,属于“集体记忆”了。如果当前的leader宕机再次发生选举,只有拥有完整已提交日志的server才能够获得多数派选票,才能被选举为leader。根据Leader完整性(Leader Completeness),如果一个日志项在某个term被提交了,则该Entry会存在于所有更高term的leader日志中。
lastApplied: 应用(apply)给状态机的最高日志项的index,也就是上层应用“消费”到Raft日志项的最新index。Leader使用nextIndex和matchIndex两个数组来维护集群中其它server的日志状态。
其他结构体字段:
- applyCh: 由实验提供,通过该channel将ApplyMsg发送给上层应用。
- moreApply: 示意有更多的日志项已经被提交,可以apply。
- applyCond: apply时用于多goroutine之间同步的Condition。
Start函数
Start函数是raft顶层的服务最开始调用的类似初始化的函数
如果server不是leader则返回false。如果是leader的话,那么将command组装成LogEntry后追加到自己的日志中。此处要同时更新leader自己的matchIndex(由于自己就是Leader,自己肯定与自己一致)和nextIndex(如果自己是Follower,这条日志肯定就不能改了)
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := false
// Your code here (2B).
if !rf.killed() {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state == Leader {
isLeader = true
// 只有是Leader才可以接收日志信息
// 添加日志信息
rf.log = append(rf.log, LogEntry{
Term: rf.currentTerm,
Command: command,
})
index = len(rf.log) - 1
term = rf.currentTerm
rf.matchIndex[rf.me] = index // 已经复制给他的日志的最高索引值
rf.nextIndex[rf.me] = index + 1 // 需要发送给他的下⼀个日志条目的索引值
}
// 论文与代码起始位置索引不同
index += 1
}
return index, term, isLeader
}两个RPC的新增字段
请求投票RPC:新增了最后一个日志项的信息
- LastLogIndex 是 candidate 最后一个日志项的 index
- LastLogTerm 是 candidate 最后一个日志项的 term
新增日志RPC:(只有Leader才可能发出)
- Entries[]: 发送给对应server的新日志,如果是心跳则为空。这里要发送给对应server日志的index,是从nextIndex到最后一个日志项的index,注意也可能为空。
- PrevLogIndex: 紧跟在新日志之前的日志项的index,是leader认为follower当前可能已经同步到了的最高日志项的index。对于第i个server,就是nextIndex[i] - 1。
- PrevLogTerm: prevLogIndex对应日志项的term。
- LeaderCommit: leader已经提交的commit index。用于通知follower更新自己的commit index。
AppendEntryReply结构体新增了XTerm、XIndex和XLen几个变量用于nextIndex的快速回退。
论文中的nextIndex在AppendEntry RPC返回不匹配后,默认只是回退一个日志项(nextIndex[i]=PrevLogIndex)。如果follower能够返回更多信息,那么leader可以根据这些信息使对应server的nextIndex快速回退,减少AppendEntry RPC通信不匹配的次数,从而加快同步日志的步伐。这几个变量的具体含义:
- XLen: 当前follower所拥有的的日志长度。
- XTerm: 当前follower的日志中,PrevLogIndex所对应日志项的term。可能为空。
- XIndex: 当前follower的日志中,拥有XTerm的日志项的最低index,可能为空。
主函数 Make
make()函数中除做一些初始化的工作之外,新增了将已经被提交的日志项返回给上层应用的goroutine
// 初始化日志相关
rf.log = make([]LogEntry, 0)
rf.commitIndex = -1
rf.lastApplied = -1
rf.nextIndex = make([]int, len(peers))
rf.matchIndex = make([]int, len(peers))
rf.applyCh = applyCh
rf.moreApply = false
rf.applyCond = sync.NewCond(&rf.mu)
go rf.appMsgApplier()这个新增的goroutine无限循环判断rf.moreApply字段,一旦发现为真,则触发返回的操作,返回新的提交过的日志给上层应用
func (rf *Raft) sendApplyMsg() {
rf.moreApply = true
rf.applyCond.Broadcast()
}
func (rf *Raft) appMsgApplier() {
for {
rf.mu.Lock()
// 等待这个字段为真才可以继续
for !rf.moreApply {
rf.applyCond.Wait()
}
rf.moreApply = false
commitIndex := rf.commitIndex
lastApplied := rf.lastApplied
entries := rf.log
rf.mu.Unlock()
// 发送已经提交但是还没有返回的日志字段
for i := lastApplied + 1; i <= commitIndex; i++ {
msg := ApplyMsg{
CommandValid: true,
Command: entries[i].Command,
CommandIndex: i + 1,
}
DPrintf("[%d]: apply index %d - 1", rf.me, msg.CommandIndex)
rf.applyCh <- msg
// 及时加锁更新,否则可能会变化
rf.mu.Lock()
rf.lastApplied = i
rf.mu.Unlock()
}
}
}返回给上层应用的情况两种:
- Leader在将日志项复制到多数派后更新commitIndex的同时,要调用sendApplyMsg()
- Follower在AppendEntry RPC收到LeaderCommit的更新时,也要调用sendApplyMsg()
选举限制
在前面选举Leader时,并没有对日志做限制,在这里需要补充日志层面的选举限制
首先要在请求投票的结构体中附带自己最后一条日志的信息
// Candidate最后一条日志的信息
lastLogIndex := len(rf.log) - 1
lastLogTerm := -1
// 如果日志为空需要添加判断
if lastLogIndex != -1 {
lastLogTerm = rf.log[lastLogIndex].Term
}
args := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: lastLogIndex,
LastLogTerm: lastLogTerm,
}然后严格按照论文说明对请求投票的双方进行判断即可:
总体原则:candidate的log是否至少和接受者的log一样新
- 我的log长度为0,那我肯定投票给他了
len(rf.log) ==0 - candidate的最后的log的任期比我的最后的log的任期大
args.LastLogTerm > rf.log[len(rf.log)-1].Term - candidate的最后的log的任期和我的最后的log的任期相同
args.LastLogTerm == rf.log[len(rf.log)-1].Term,但是它的日志长度比我长或一样(它先请求我投票,那么我就投票给他吧)args.LastLogIndex >=len(rf.log)-1
// 是否没投票或者投给的是这个candidate
if rf.votedFor == -1 || rf.votedFor == args.CandidateId {
// candidate的log是否至少和接受者的log一样新
// 1. 我的log长度为0,那我肯定投票给他了
// 2. candidate的最后的log的任期比我的最后的log的任期大
// 3. candidate的最后的log的任期和我的最后的log的任期相同,但是它的日志长度比我长
if len(rf.log) == 0 || (args.LastLogTerm > rf.log[len(rf.log)-1].Term) ||
(args.LastLogTerm == rf.log[len(rf.log)-1].Term && args.LastLogIndex >= len(rf.log)-1) {
rf.votedFor = args.CandidateId
rf.lastReceive = time.Now().Unix() // 更新时间,上面操作相当于与可能的Leader通信过了
reply.VoteGranted = true
DPrintf("[%d]: voted to [%d]", rf.me, args.CandidateId)
}
}日志复制
前期准备(构建请求)
// 找到日志的同步位置
prevLogIndex := rf.nextIndex[index] - 1
prevLogTerm := -1
if prevLogIndex != -1 {
prevLogTerm = rf.log[prevLogIndex].Term
}
// 找到要发送的日志
var entries []LogEntry
if len(rf.log)-1 >= rf.nextIndex[index] {
entries = rf.log[rf.nextIndex[index]:]
}
// 补充结构体
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
LeaderCommit: rf.commitIndex,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
Entries: entries,
}论文的日志匹配性质:
- 如果来自不同日志的两个日志项有相同的index和term,那么它们存储了相同的command。
- 如果来自不同日志的两个日志项有相同的index和term,那么它们前面的日志完全相同。
因此只需要判断PrevLogIndex和PrevLogTerm与follower的日志匹配的程度即可,这里只是Leader猜测一下,真正的判断在接收到RPC后完成
Follower处理请求
在处理AppendEntry RPC的代码中,新增了日志匹配的逻辑。
如果日志在prevLogIndex处不包含term为prevLogTerm的日志项,那么返回false,(需要回退才能找到对应的位置)。
- 接收者的日志没有index为prevLogIndex的日志项
- 有对应index的日志项但是term不匹配。
回退的逻辑:
- 记录Follower的日志的长度
- 找到prevLogIndex的索引位置的任期号并记录任期(一定比prevLogTerm更小)
- 往回遍历日志,找到第一个是上一步记录的任期的索引,那么这个位置之前一定是与Leader相同的日志,记录索引
// Reply false if log doesn’t contain an entry at prevLogIndex
// whose term matches prevLogTerm (§5.3)
if args.PrevLogIndex >= len(rf.log) || (args.PrevLogIndex >= 0 && rf.log[args.PrevLogIndex].Term != args.PrevLogTerm) {
reply.Term = rf.currentTerm
// 回退
reply.XLen = len(rf.log)
if args.PrevLogIndex >= 0 && args.PrevLogIndex < len(rf.log) {
reply.XTerm = rf.log[args.PrevLogIndex].Term
for i := args.PrevLogIndex; i >= 0; i-- {
if rf.log[i].Term == reply.XTerm {
reply.XIndex = i
} else {
break
}
}
}
return
}此外还要注意prevLogIndex可能为-1,意味着日志全都没有匹配上,或者leader此刻还没有日志,此时接收者就要完全服从。
接下来是PreLogIndex与PrevLogTerm匹配到的情况,还要额外检查新同步过来的日志和已存在的日志是否存在冲突。如果一个已经存在的日志项和新的日志项冲突(相同index但是不同term),那么要删除这个冲突的日志项及其往后的日志。
// If an existing entry conflicts with a new one (same index
// but different terms), delete the existing entry and all that
// follow it (§5.3)
misMatchIndex := -1
for i := range args.Entries {
if args.PrevLogIndex+1+i >= len(rf.log) || rf.log[args.PrevLogIndex+1+i].Term != args.Entries[i].Term {
misMatchIndex = i
break
}
}将新的日志项追加到日志中
// Append any new entries not already in the log
if misMatchIndex != -1 {
rf.log = append(rf.log[:args.PrevLogIndex+1+misMatchIndex], args.Entries[misMatchIndex:]...)
}最后根据论文,如果 leaderCommit > commitIndex,说明follower的commitIndex也需要更新。为了防止越界,commitIndex取 min(leaderCommit, index of last new entry)。同时要向上层应用发回响应。
// If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
if args.LeaderCommit > rf.commitIndex {
newEntryIndex := len(rf.log) - 1
if args.LeaderCommit >= newEntryIndex {
rf.commitIndex = newEntryIndex
} else {
rf.commitIndex = args.LeaderCommit
}
DPrintf("[%d]: commit index [%d]", rf.me, rf.commitIndex)
rf.sendApplyMsg()
}Leader处理响应
由于RPC在网络中可能乱序或者延迟,我们要确保当前RPC发送时的term、当前接收时的currentTerm以及RPC的reply.term三者一致,丢弃过去term的RPC,避免对当前currentTerm产生错误的影响。
reply.Term == rf.currentTerm && rf.currentTerm == args.Term当reply.Success为true,说明follower包含了匹配prevLogIndex和prevLogTerm的日志项,更新nextIndex[serverTo]和matchIndex[serverTo]。这里只能用prevLogIndex和entries来更新,而不能用nextIndex及len(log),因为后两者可能已经被别的RPC更新了,进而导致数据不一致。
由于matchIndex发生了变化,我们要检查是否更新commitIndex。根据论文,如果存在一个N,这个N大于commitIndex,多数派的matchIndex[i]都大于等于N,并且log[N].term等于currentTerm,那么更新commitIndex为N。这里必须注意,日志提交是有限制的,Raft从不提交过去term的日志项,即使已经复制达到了多数派。如果要更新commitIndex为N,那么N所对应的日志项的term必须是当前currentTerm。
在检查是否更新commitIndex的实现上,我们将matchIndex复制到了matches数组中,通过sort升序排序以方便遍历。然后对matches数组进行遍历,找到大多数都提交的索引位置,随后调用sendApplyMsg(),通知有更多的日志项已经被提交,上层应用可以应用。
if reply.Success {
// 更新服务器的状态
rf.nextIndex[index] = prevLogIndex + len(entries) + 1
rf.matchIndex[index] = prevLogIndex + len(entries)
// If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, and log[N].term == currentTerm:
// set commitIndex = N
matches := make([]int, len(rf.peers))
copy(matches, rf.matchIndex)
sort.Ints(matches)
for i := rf.majorityVote - 1; i >= 0 && matches[i] > rf.commitIndex; i-- {
if rf.log[matches[i]].Term == rf.currentTerm {
rf.commitIndex = matches[i]
DPrintf("[%d]: commit index [%d]", rf.me, rf.commitIndex)
rf.sendApplyMsg()
break
}
}
}当reply.Success为false,说明follower的日志不包含在prevLogIndex处并匹配prevLogTerm的日志项,要将nextIndex缩减。此处更新不宜采用自减的方式更新,因为RPC可能会重发,正确的方式是 rf.nextIndex[serverTo] = prevLogIndex。
在AppendEntryReply中增加了几个变量,以使nextIndex能够快速回退(back up)。如果接下来要尝试匹配的prevLogIndex比follower当前所拥有的的日志长度(XLen)还要大,那么显然直接从XLen尝试匹配即可。如果接下来要尝试匹配的prevLogIndex在XLen以内,因为我们已经知道了follower的日志从XIndex到当前prevLogIndex的日志项的term都是XTerm,那么我们可以直接在leader侧遍历匹配一遍,而无需多次往返RPC通信。
} else {
// In Test (2C): Figure 8 (unreliable), the AppendEntry RPCs are reordered
// So rf.nextIndex[index]-- would be wrong
rf.nextIndex[index] = prevLogIndex
// 如果接下来要尝试匹配的prevLogIndex比follower当前所拥有的的日志长度(XLen)还要大,那么显然直接从XLen尝试匹配即可。
if rf.nextIndex[index]-1 >= reply.XLen {
rf.nextIndex[index] = reply.XLen
} else {
// 如果接下来要尝试匹配的prevLogIndex在XLen以内,因为我们已经知道了follower的日志从XIndex到当前prevLogIndex的日志项的term都是XTerm,那么我们可以直接在leader侧遍历匹配一遍,而无需多次往返RPC通信
for i := rf.nextIndex[index] - 1; i >= reply.XIndex; i-- {
if rf.log[i].Term != reply.XTerm {
rf.nextIndex[index] -= 1
} else {
break
}
}
}
}运行结果
Test (2B): basic agreement ...
... Passed -- 1.3 3 16 4546 3
Test (2B): RPC byte count ...
... Passed -- 2.7 3 48 114510 11
Test (2B): agreement after follower reconnects ...
... Passed -- 7.1 3 116 31767 8
Test (2B): no agreement if too many followers disconnect ...
... Passed -- 4.1 5 160 37664 3
Test (2B): concurrent Start()s ...
... Passed -- 1.2 3 12 3466 6
Test (2B): rejoin of partitioned leader ...
... Passed -- 5.6 3 166 40233 4
Test (2B): leader backs up quickly over incorrect follower logs ...
... Passed -- 34.1 5 2352 2038228 102
Test (2B): RPC counts aren't too high ...
... Passed -- 2.5 3 42 12630 12
PASS
ok 6.824/raft 58.652s
real 0m59.353s
user 0m1.744s
sys 0m1.630sPart 2C:持久性
指导
如果基于 Raft 的服务器重新启动,它应该在中断的地方恢复服务。这要求 Raft 在重启后,依旧能确保数据持久化。本文的Figure 2 提到的那些状态应该被持久化。
真正的实现会在每次 persistent state 被修改时写磁盘,并在重新启动后从磁盘读取状态。您不需要使用磁盘,而应该通过 Persister 对象保存和恢复 persistent state (请参阅 persister.go)。调用 Raft.Make()时会提供一个 Persister, 其可能会包含 Raft 最近的 persistent state(也可能没有) 。Raft 应从 Persister 初始化其状态(对应方法 ReadRaftState()),并在每次 president state 更改后使用 Persister 保存(对应方法 SaveRaftState())。
完善 raft.go中的 persist()和 readPerisit()函数,实现保存和读取 persistent state。你可能需要使用 labgob encoder 来编码(或者说序列化)persistent state,让 Persister来存储二进制流。欢迎查看 persist()和 readPerisit()的注释了解更多。labgob很像 go 的 gob,只是会在序列化非导出字段时报错。实现完“ 在每次 persistent state 改变时调用 presist()”后,应通过其余测试。
您可能想优化为一次性保存多条日志。查看论文第7页的顶部到第 8 页顶部(用灰色线标记的地方)。论文没有描述清楚细节,你需要自己多考虑一下。 6.824 Raft 的讲座或许也能提供一些帮助。
您的代码应通过所有 2C 测试:
$ go test -run 2C
Test (2C): basic persistence ...
... Passed -- 5.0 3 86 22849 6
Test (2C): more persistence ...
... Passed -- 17.6 5 952 218854 16
Test (2C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 2.0 3 34 8937 4
Test (2C): Figure 8 ...
... Passed -- 31.2 5 580 130675 32
Test (2C): unreliable agreement ...
... Passed -- 1.7 5 1044 366392 246
Test (2C): Figure 8 (unreliable) ...
... Passed -- 33.6 5 10700 33695245 308
Test (2C): churn ...
... Passed -- 16.1 5 8864 44771259 1544
Test (2C): unreliable churn ...
... Passed -- 16.5 5 4220 6414632 906
PASS
ok 6.824/raft 123.564s
$最好能多次运行:for i in {0..10}; do go test; done
实现
Part 2D:日志压缩
指导
就目前情况而言,重新启动的服务器会重放完整的Raft日志,以恢复其状态。然而,对于长期运行的服务来说,永远记住完整的Raft日志是不现实的。相反,您将修改Raft以与持久存储其状态的“快照”的服务协作,此时Raft将丢弃快照之前的日志条目。其结果是持久数据量更少,重启速度更快。然而,现在有可能一个追随者远远落后,以至于领导者放弃了需要追赶的日志条目;然后领导者必须发送快照以及快照时开始的日志。
您的Raft必须提供以下函数 Snapshot(index int, snapshot []byte),服务可以使用其状态的序列化快照调用该函数。
在Lab 2D中,测试代码定期调用 Snapshot()。在Lab 3中,您将编写一个k/v服务器调用 Snapshot();快照将包含k/v对的完整表。服务层对每个对等方(而不仅仅是Leader)调用 Snapshot()。
index参数指示快照中包括的最高日志条目。raft应该在这个参数之前丢弃其日志条目。您需要修改Raft代码以只存储日志尾部。
您需要实现论文中讨论的 InstallSnapshot RPC,该RPC允许raft的Leader告诉落后的Raft服务器用快照替换其状态。您可能需要考虑 InstallSnapshot应该如何与图2中的状态和规则交互。
当Follower的Raft代码接收到 InstallSnapshot RPC时,它可以使用 applyCh将快照发送到 ApplyMsg中的服务。ApplyMsg结构定义已经包含了您需要的字段(并且是测试代码期望的)。请注意,这些快照只会增加服务的状态,而不会导致服务向后移动。
如果服务器崩溃,它必须从持久数据重新启动。您的Raft应该保持Raft状态和相应的快照。使用 persister.SaveStateAndSnapshot(),它对于Raft状态和相应的快照有单独的参数。如果没有快照,则传递nil作为快照参数。
当服务器重新启动时,应用程序层读取持久化快照并恢复其保存状态。
以前,建议您实现一个名为 CondInstallSnapshot的函数,以避免在 applyCh上发送的快照和日志条目需要协调。这个残留的API接口仍然存在,但不希望实现它:相反,我们建议您只需将其返回true。
任务:实现 Snapshot()和 InstallSnapshot RPC,以及对Raft的更改以支持这些(例如,使用修剪日志的操作)。
提示:
- 修改代码以便能够存储从某个索引X开始的日志部分是一个好的开始。最初,您可以将X设置为零并运行2B/2C测试。然后使用
Snapshot(index)放弃索引之前的日志,并将X设置为索引。如果一切顺利,您现在应该通过第一个2D测试。 - 您将无法将日志存储在Go切片中,并将Go切片索引与Raft日志索引互换使用;您需要以一种方式对切片进行索引,以说明日志中被丢弃的部分。
- 下一步:如果Leader没有更新Follower所需的日志条目,则让Leader发送
InstallSnapshot RPC。 - 在单个
InstallSnapshot RPC中发送整个快照。不要实现图13的用于分割快照的偏移机制。 - Raft必须以允许Go垃圾收集器释放和重新使用内存的方式丢弃旧日志条目;这要求对丢弃的日志条目没有可访问的引用(指针)。
- 即使日志被修剪,您的实现仍然需要在
AppendEntries RPC中的新条目之前正确发送条目的术语和索引;这可能需要保存和引用最新快照的lastIncludedTerm/lastIncludedIndex(请考虑是否应持久化)。 - 在不检测竞争的情况下,全套Lab 2测试(2A+2B+2C+2D)所需的合理时间是6分钟的实时时间和1分钟的CPU时间。使用–race运行时,大约需要10分钟的实时时间和2分钟的CPU时间。
输出示例:
$ go test -run 2D
Test (2D): snapshots basic ...
... Passed -- 11.6 3 176 61716 192
Test (2D): install snapshots (disconnect) ...
... Passed -- 64.2 3 878 320610 336
Test (2D): install snapshots (disconnect+unreliable) ...
... Passed -- 81.1 3 1059 375850 341
Test (2D): install snapshots (crash) ...
... Passed -- 53.5 3 601 256638 339
Test (2D): install snapshots (unreliable+crash) ...
... Passed -- 63.5 3 687 288294 336
Test (2D): crash and restart all servers ...
... Passed -- 19.5 3 268 81352 58
PASS
ok 6.824/raft 293.456s