Pytorch分布式训练
Pytorch分布式训练学习整理
参考资料
源码解析:PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析
简单小模型示例:pytorch中分布式训练DDP教程(新手快速入门!)
系列文章:【分布式训练】单机多卡的正确打开方式(一):理论基础
【分布式训练】基于PyTorch进行多GPU分布式模型训练(补充)
较新较详细的教程:torch分布式训练
模型并行(流水线)
把模型隔成不同的层,每一层都放到一块GPU上
(1)GPU利用度不够。
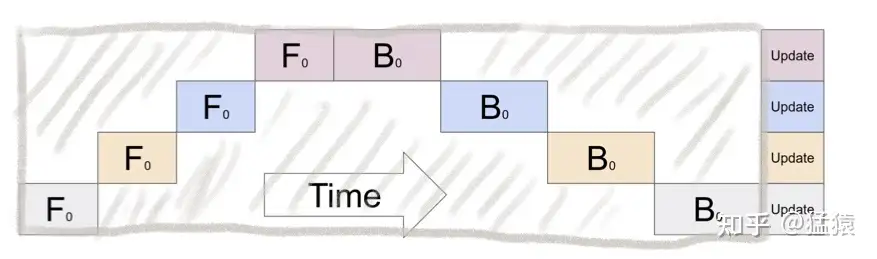
如图,阴影部分所表示的时间段里,总有GPU在空转。GPU的数量越多时,空置的比例接近1
(2)中间结果占据大量内存
在做backward计算梯度的过程中,我们需要用到每一层的中间结果z。假设我们的模型有L层,每一层的宽度为d,则对于每块GPU,不考虑其参数本身的存储,额外的空间复杂度为
Gpipe
流水线并行的核心思想是: 在模型并行的基础上,进一步引入数据并行的办法,即把原先的数据再划分成若干个batch,送入GPU进行训练 。未划分前的数据,叫 mini-batch 。在mini-batch上再划分的数据,叫 micro-batch 。
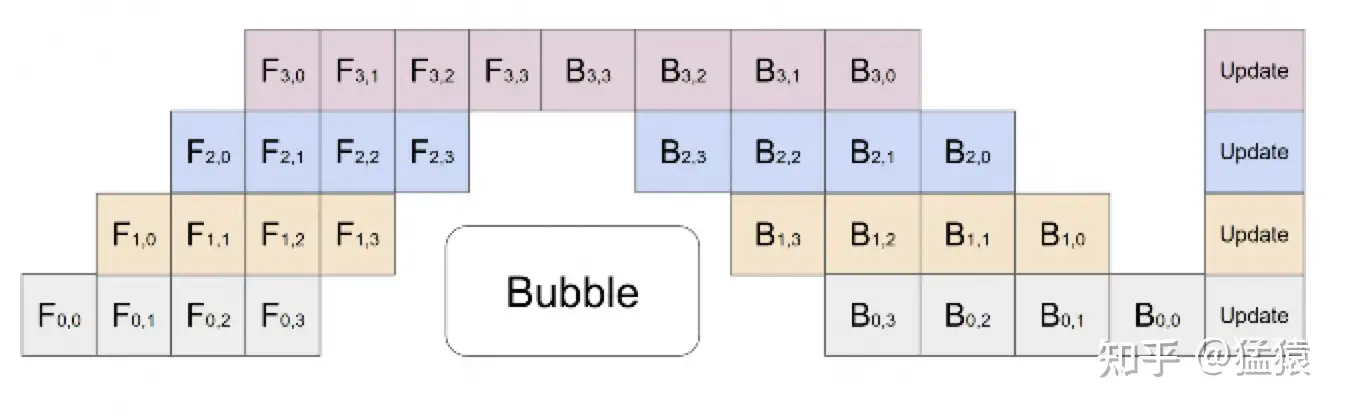
其中,第一个下标表示GPU编号,第二个下标表示micro-batch编号。假设我们将mini-batch划分为M个,则流水线并行下,bubble的时间复杂度为:
将batch切好,并逐一送入GPU的过程,就像一个流水生产线一样(类似于CPU里的流水线),因此也被称为Pipeline Parallelism。
Gpipe采用用时间换空间的方法,几乎不存中间结果,等到backward的时候,再重新算一遍forward
每块GPU上只保存来自上一块的最后一层输入z,其余的中间结果我们算完就废。等到backward的时候再由保存下来的z重新进行forward来算出。
空间复杂度为
在实际应用中,流水线并行并不特别流行,主要原因是模型能否均匀切割,影响了整体计算效率,这就需要算法工程师做手调。
数据并行
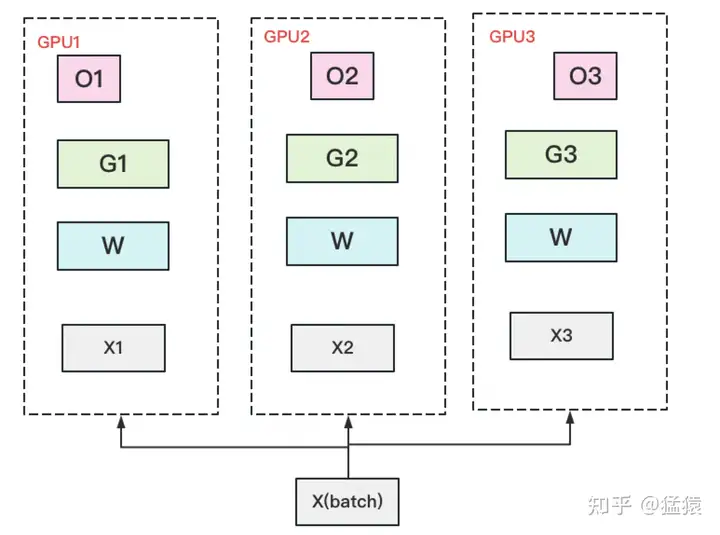
数据并行的核心思想是: 在各个GPU上都拷贝一份完整模型,各自吃一份数据,算一份梯度,最后对梯度进行累加来更新整体模型 。理念不复杂,但到了大模型场景, 巨大的存储和GPU间的通讯量, 就是系统设计要考虑的重点了。在本文中,我们将递进介绍三种主流数据并行的实现方式:
- DP(Data Parallelism) :最早的数据并行模式,一般采用参数服务器(Parameters Server)这一编程框架。实际中多用于单机多卡
- DDP(Distributed Data Parallelism) :分布式数据并行,采用Ring AllReduce的通讯方式,实际中多用于多机场景
- ZeRO: 零冗余优化器。由微软推出并应用于其DeepSpeed框架中。严格来讲ZeRO采用数据并行+张量并行的方式,旨在降低存储。
DP
一个经典数据并行的过程如下:
- 若干块 计算GPU ,如图中GPU0~GPU2;1块 梯度收集GPU ,如图中AllReduce操作所在GPU。
- 在每块计算GPU上都拷贝一份完整的模型参数。
- 把一份数据X(例如一个batch)均匀分给不同的计算GPU。
- 每块计算GPU做一轮FWD和BWD后,算得一份梯度G。
- 每块计算GPU将自己的梯度push给梯度收集GPU,做聚合操作。这里的聚合操作一般指 梯度累加 。当然也支持用户自定义。
- 梯度收集GPU聚合完毕后,计算GPU从它那pull下完整的梯度结果,用于更新模型参数W。更新完毕后,计算GPU上的模型参数依然保持一致。
- 聚合再下发梯度的操作,称为AllReduce 。
流程

DP 基于单机多卡,所有设备都负责计算和训练网络,除此之外, device[0] (并非 GPU 真实标号而是输入参数 device_ids 首位) 还要负责整合梯度,更新参数。从图中我们可以看出,有三个主要过程:
- 过程一(图中红色部分):各卡分别计算损失和梯度
- 过程二(图中蓝色部分):所有梯度整合到 device[0]
- 过程三(图中绿色部分):device[0] 进行参数更新,其他卡拉取 device[0] 的参数进行更新
所有卡都并行运算(图中红色),将梯度收集到 device[0](图中浅蓝色)和 device[0] 分享模型参数给其他 GPU(图中绿色)三个主要过程。
更详细的流程如下图所示:
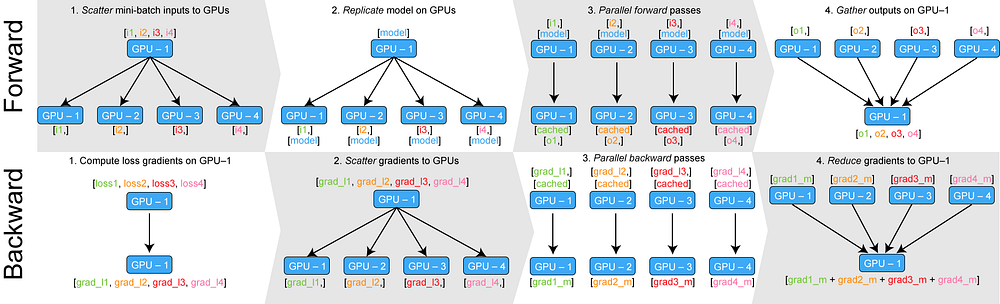
分析
- 存储开销大 。每块GPU上都存了一份完整的模型,造成冗余。
- 通讯开销大 。Server需要和每一个Worker进行梯度传输。当Server和Worker不在一台机器上时,Server的带宽将会成为整个系统的计算效率瓶颈。
梯度异步更新:Worker并不会实际等到把聚合梯度拿回来,更新完参数W后再做计算。而是直接拿旧的W,吃新的数据,继续第11轮的计算。这样就保证在通讯的时间里,Worker也在马不停蹄做计算,提升计算通讯比。
但是模型收敛的速度不会变快,只是多用了一些数据
受通讯负载不均的影响, DP一般用于单机多卡场景 。
DDP
DDP作为一种更通用的解决方案出现了,既能多机,也能单机。DDP首先要解决的就是通讯问题:将Server上的通讯压力均衡转到各个Worker上。实现这一点后,可以进一步去Server,留Worker。
简介
随着大模型的出现,简单的数据并行已经无法满足需求,毕竟一个模型的大小就有可能超过显卡的显存,更不可能将其复制多份。因此需要让每一张卡仅负责模型的一部分计算,承载模型的一小部分。
使用DDP进行分布式训练有以下几个优势:
- 加速训练:通过数据并行,DDP能够在多个设备或节点上同时处理不同批次的数据,从而加快训练速度。
- 内存效率:DDP在每个设备上只保存模型的局部副本和相应的梯度,而不是整个模型的副本,这样可以节省内存。
- 不需要额外的代码:在PyTorch中,使用DDP进行分布式训练几乎不需要修改您的原始模型和训练代码。
流程:Ring All Reduce
Scatter Reduce过程:首先将参数分为

All Gather:得到每一份参数的累积之后,再做一次传递,同步到所有的GPU上。
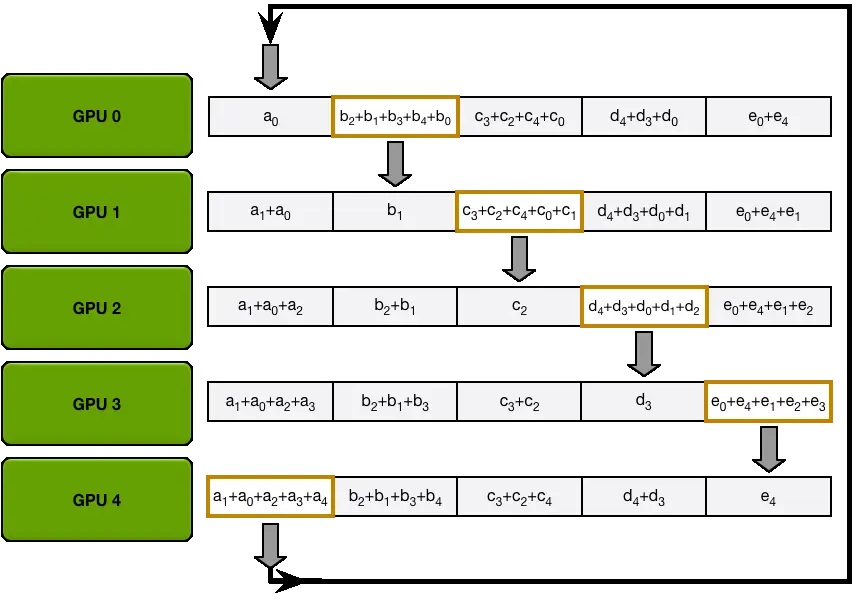
假设有
DP和DDP的总通讯量相同,但因负载不均的原因,DP需要耗费更多的时间搬运数据,但是DP不一定就比DDP差
代码
分析
DDP采用多进程控制多GPU,共同训练模型,一份代码会被pytorch自动分配到n个进程并在n个GPU上运行。 DDP运用Ring-Reduce通信算法在每个GPU间对梯度进行通讯,交换彼此的梯度,从而获得所有GPU的梯度。对比DP,不需要在进行模型本体的通信,因此可以加速训练。
需要注意以下几点:
- 设置DistributedSampler来打乱数据,因为一个batch被分配到了好几个进程中,要确保不同的GPU拿到的不是同一份数据。
- 要告诉每个进程自己的id,即使用哪一块GPU。
- 如果需要做BatchNormalization,需要对数据进行同步。
Torchrun使用及参数详解
核心概念
- rank:进程号,在多进程上下文中,我们通常假定rank 0是第一个进程或者主进程,其它进程分别具有1,2,3不同rank号,这样总共具有4个进程。
- node:物理节点,可以是一个容器也可以是一台机器,节点内部可以有多个GPU;nnodes指物理节点数量, nproc_per_node指每个物理节点上面进程的数量
- local_rank:指在一个node上进程的相对序号,local_rank在node之间相互独立
- WORLD_SIZE:全局进程总个数,即在一个分布式任务中rank的数量
- Group:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group
- backend:通信后端,可选的包括:nccl(NVIDIA推出)、gloo(Facebook推出)、mpi(OpenMPI)。一般建议GPU训练选择nccl,CPU训练选择gloo
- master_addr与master_port:主节点的地址以及端口,供init_method 的tcp方式使用。 因为pytorch中网络通信建立是从机去连接主机,运行ddp只需要指定主节点的IP与端口,其它节点的IP不需要填写。
如下图所示,共有3个节点(机器),每个节点上有4个GPU,每台机器上起4个进程,每个进程占一块GPU,那么图中一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都有一个对应的node_rank

rank与GPU之间没有必然的对应关系,一个rank可以包含多个GPU;一个GPU也可以为多个rank服务(多进程共享GPU),在torch的分布式训练中习惯默认一个rank对应着一个GPU,因此local_rank可以当作GPU号
简介
torchrun相当于原来的torch.distributed.launch,有一些额外增加的功能:
- 通过重启优雅处理某一个worker运行过程中的错误
- worker的RANK和WORLD_SIZE都是被自动分配的
- Node的数量允许从最小值到最大值中间弹性伸缩
torchrun命令与 python -m torch.distributed.run命令完全等同,为命令行命令
从旧版本迁移 --use_env
有一个参数 --use_env在目前版本的torchrun中是不存在的,因此需要做一点处理
- 将原始指定的–local-rank参数修改为从环境变量中读取
- 命令行不需要再次指定
--use_env参数
旧版本代码:
$ python -m torch.distributed.launch --use-env train_script.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local-rank", type=int)
args = parser.parse_args()
local_rank = args.local_rank新版本代码:
$ torchrun train_script.py
import os
local_rank = int(os.environ["LOCAL_RANK"])命令行参数
| 参数名称 | 含义 | 示例 |
|---|---|---|
| –nnodes | 节点数量,一个节点对应一个主机 | 1或MIN_SIZE:MAX_SIZE(弹性训练) |
| –nproc-per-node | 一个节点中的进程数量,一般一个进程使用一个显卡,故也通常表述为一个节点中显卡的数量 | [auto, cpu, gpu, int] |
| –rdzv-backend | rendezvous 后端 | c10d etcd |
| –rdzv-endpoint | rendezvous 后端地址 | <host>:<port> |
| –rdzv-id | 用户可以指定当前rendezvous的id,所有的node都要使用这同一个id | |
| –rdzv-conf | 希望传入rendezvous的其他参数 | <key1>=<value1> |
| –standalone | 单节点多卡的默认配置,不需要再传入上述的rendezvous参数,默认为C10d TCP 29400(–master-addr等也会失效) | 选项 |
| –max-restarts | worker group重启的最大次数 | |
| –monitor-interval | 检测worker状态的时间间隔(以秒为单位) | |
| –start-method | 创建子进程的方式 | {spawn,fork,forkserver} |
| –role | User-defined role for the workers. | |
| -m | 与python -m相同,将模块当作脚本运行 | 选项 |
| –no-python | 不使用python命令而是直接执行(如果这个文件并不是一个py文件会使用这个) | |
| –run-path | 使用runpy.run_path执行文件 | |
| –log-dir | 日志文件存放目录 | |
| –redirects | 将控制台输出的日志信息重定向到日志目录中的文件 | [-r 3] 将所有worker的标准输出和标准错误进行重定向,[-r 0:1,1:2] 将rank 0的标准输出重定向,将rank 1的标准错误重定向 |
| –tee | 除将日志输出到控制台外也输出到日志文件 | 日志文件流 |
| –node-rank | 多节点分布式训练的时候该节点的Rank | |
| –master-addr | master 节点的 IP 地址,也就是 rank=0 对应的主机地址 | |
| –master-port | master 节点的端口号,用于通信 | |
| –local-addr | 本地节点的IP地址 |
torchrun主要是对多节点作了分布式的优化,从而可以满足容错性和弹性伸缩。如果是单节点就不需要很复杂。
环境变量
| 名称 | 含义 | 示例 | |
|---|---|---|---|
| LOCAL_RANK | GPU在单节点中的序号 | 0 | 1 |
| RANK | GPU在全部节点的序号 | 0 | 1 |
| GROUP_RANK | worker组的rank | 0 | 0 |
| ROLE_RANK | 相同ROLE的worker的rank | 0 | 1 |
| LOCAL_WORLD_SIZE | 与–nproc-per-node相同 | 2 | 2 |
| WORLD_SIZE | job中worker的总数 | 2 | 2 |
| ROLE_WORLD_SIZE | 相同角色的worker的数量 | 1 | 2 |
| MASTER_ADDR | rank为0的worker的地址 | 127.0.0.1 | 127.0.0.1 |
| MASTER_PORT | rank为0的worker的端口 | 29500 | 29500 |
| TORCHELASTIC_RESTART_COUNT | 最近重启的worker组的数量 | 0 | 0 |
| TORCHELASTIC_MAX_RESTARTS | 配置的最大重启次数 | 0 | 0 |
| TORCHELASTIC_RUN_ID | 与–rdzv-id相同 | none | none |
| PYTHON_EXEC | 执行这个脚本的python的位置 | 没有 | 没有 |
代码示例
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
from torch.distributed import init_process_group, destroy_process_group
import os
import time
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
class MyTrainDataset(Dataset):
def __init__(self, size):
self.size = size
self.data = [(torch.rand(10), 0) for _ in range(size)]
def __len__(self):
return self.size
def __getitem__(self, index):
return self.data[index]
class Trainer:
def __init__(
self,
model: torch.nn.Module,
train_data: DataLoader,
optimizer: torch.optim.Optimizer,
save_every: int,
snapshot_path: str,
) -> None:
self.gpu_id = int(os.environ["LOCAL_RANK"])
self.model = model.to(self.gpu_id)
self.train_data = train_data
self.optimizer = optimizer
self.save_every = save_every
self.epochs_run = 0
self.snapshot_path = snapshot_path
if os.path.exists(snapshot_path):
print("Loading snapshot")
self._load_snapshot(snapshot_path)
self.model = DistributedDataParallel(self.model, device_ids=[self.gpu_id])
def _load_snapshot(self, snapshot_path):
loc = f"cuda:{self.gpu_id}"
snapshot = torch.load(snapshot_path, map_location=loc)
self.model.load_state_dict(snapshot["MODEL_STATE"])
self.epochs_run = snapshot["EPOCHS_RUN"]
print(f"Resuming training from snapshot at Epoch {self.epochs_run}")
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
# print(output,targets)
loss = F.cross_entropy(output, targets)
print(f"[GPU{self.gpu_id}] Loss {loss.item()}")
loss.backward()
self.optimizer.step()
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
self.train_data.sampler.set_epoch(epoch)
for source, targets in self.train_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
self._run_batch(source, targets)
def _save_snapshot(self, epoch):
snapshot = {
"MODEL_STATE": self.model.module.state_dict(),
"EPOCHS_RUN": epoch,
}
torch.save(snapshot, self.snapshot_path)
print(f"Epoch {epoch} | Training snapshot saved at {self.snapshot_path}")
def train(self, max_epochs: int):
for epoch in range(self.epochs_run, max_epochs):
self._run_epoch(epoch)
if self.gpu_id == 0 and epoch % self.save_every == 0:
self._save_snapshot(epoch)
time.sleep(1)
def ddp_setup():
init_process_group(backend="nccl")
print("Parameters")
print(f"LOCAL_RANK:{os.environ['LOCAL_RANK']}")
print(f"RANK:{os.environ['RANK']}")
print(f"GROUP_RANK:{os.environ['GROUP_RANK']}")
print(f"ROLE_RANK:{os.environ['ROLE_RANK']}")
print(f"LOCAL_WORLD_SIZE:{os.environ['LOCAL_WORLD_SIZE']}")
print(f"WORLD_SIZE:{os.environ['WORLD_SIZE']}")
print(f"ROLE_WORLD_SIZE:{os.environ['ROLE_WORLD_SIZE']}")
print(f"MASTER_ADDR:{os.environ['MASTER_ADDR']}")
print(f"MASTER_PORT:{os.environ['MASTER_PORT']}")
print("")
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
def load_train_objs():
train_set = MyTrainDataset(2048) # load your dataset
model = ToyModel()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
return train_set, model, optimizer
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(dataset)
)
def main(save_every: int, total_epochs: int, batch_size: int, snapshot_path: str = "snapshot.pt"):
ddp_setup()
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, save_every, snapshot_path)
trainer.train(total_epochs)
destroy_process_group()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('--total_epochs', default=10, type=int, help='Total epochs to train the model')
parser.add_argument('--save_every', default=2, type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=512, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
main(args.save_every, args.total_epochs, args.batch_size)与单卡有几点不同:
- 初始化进程组:
init_process_group(backend="nccl"),后端一般选择nccl - 分布式数据采样器:
sampler=DistributedSampler(dataset) - 封装模型:
self.model = DistributedDataParallel(self.model, device_ids=[self.gpu_id]) - 启动torchrun脚本进行训练
训练脚本:
- 单机多卡
torchrun \
--nnodes=1 \
--nproc_per_node=2 \
--master-addr=127.0.0.1 \
--master-port=29500 \
main.py- 多机多卡
export NCCL_DEBUG=info
export NCCL_SOCKET_IFNAME=bond0
export NCCL_IB_DISABLE=1
torchrun \
--nnodes=2 \
--nproc_per_node=2 \
--master-addr=10.208.58.27 \
--master-port=29602 \
--node-rank=0 \
main.pyexport NCCL_DEBUG=info
export NCCL_SOCKET_IFNAME=bond0
export NCCL_IB_DISABLE=1
torchrun \
--nnodes=2 \
--nproc_per_node=1 \
--master-addr=10.208.58.27 \
--master-port=29602 \
--node-rank=1 \
main.py注意事项:
- 多进程训练,也就是会同时运行多份代码,因此训练时候要想好GPU的序号等需要自己指定的变量
- 数据是按照进程数量分的,比如总共2048条,如果三个进程就每一个进程683
测试环境:
master:10.208.58.27 2*V100
Parameters
LOCAL_RANK:0
RANK:0
GROUP_RANK:0
ROLE_RANK:0
LOCAL_WORLD_SIZE:2
WORLD_SIZE:3
ROLE_WORLD_SIZE:3
MASTER_ADDR:10.208.58.27
MASTER_PORT:29602
Parameters
LOCAL_RANK:1
RANK:1
GROUP_RANK:0
ROLE_RANK:1
LOCAL_WORLD_SIZE:2
WORLD_SIZE:3
ROLE_WORLD_SIZE:3
MASTER_ADDR:10.208.58.27
MASTER_PORT:29602worker:1*A100
Parameters
LOCAL_RANK:0
RANK:2
GROUP_RANK:1
ROLE_RANK:2
LOCAL_WORLD_SIZE:1
WORLD_SIZE:3
ROLE_WORLD_SIZE:3
MASTER_ADDR:10.208.58.27
MASTER_PORT:29602ZeRO(零冗余优化)
数据并行中,每个GPU上都复制了一份完整模型,当模型变大时,很容易打爆GPU的显存
存储消耗
存储主要分为两大块:Model States和Residual States
Model States指和模型本身息息相关的,必须存储的内容,具体包括:
- optimizer states :Adam优化算法中的momentum和variance
- gradients :模型梯度
- parameters :模型参数W
Residual States指并非模型必须的,但在训练过程中会额外产生的内容,具体包括:
- activation :激活值。在流水线并行中我们曾详细介绍过。在backward过程中使用链式法则计算梯度时会用到。有了它算梯度会更快,但它不是必须存储的,因为可以通过重新做Forward来算它。
- temporary buffers: 临时存储。例如把梯度发送到某块GPU上做加总聚合时产生的存储。
- unusable fragment memory :碎片化的存储空间。虽然总存储空间是够的,但是如果取不到连续的存储空间,相关的请求也会被fail掉。对这类空间浪费可以通过内存整理来解决。
精度混合训练
- 存储一份fp32的parameter,momentum和variance(统称model states)
- 在forward开始之前,额外开辟一块存储空间,将fp32 parameter减半到fp16 parameter。
- 正常做forward和backward,在此之间产生的activation和gradients,都用fp16进行存储。
- 用fp16 gradients去更新fp32下的model states。
- 当模型收敛后,fp32的parameter就是最终的参数输出。
存储大小
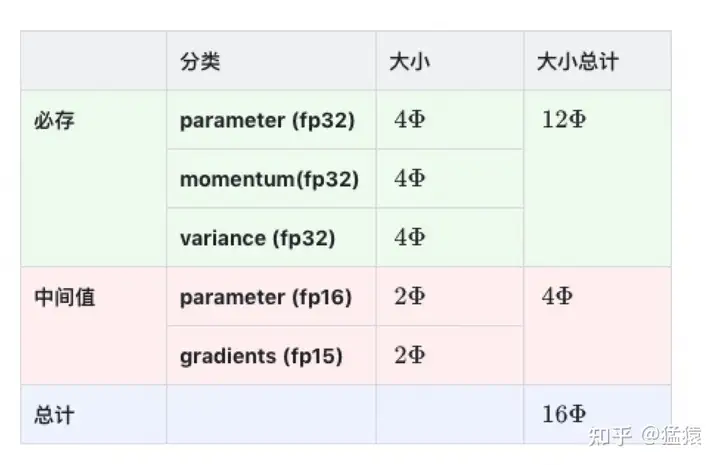
其中很大的momentum和variance是Adam保存的,首先就优化他们
ZeRO-DP
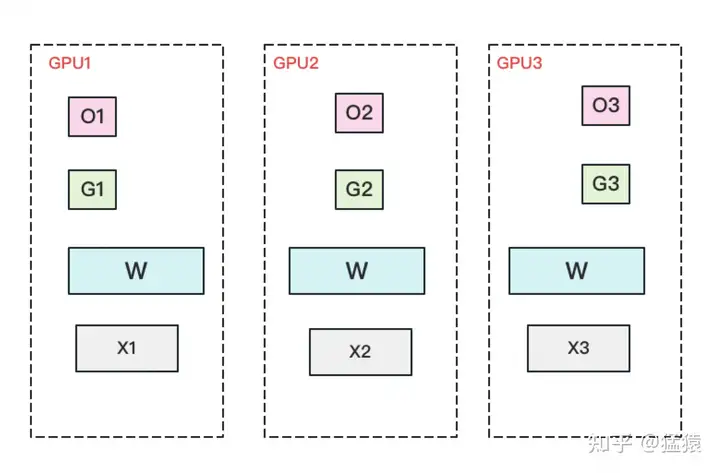
优化状态分割
将optimizer state分成若干份,每块GPU上各自维护一份。这样就减少了相当一部分的显存开销。
得到G是与DP一样的通信,然后还要聚合W
显存和通讯量的情况如下:

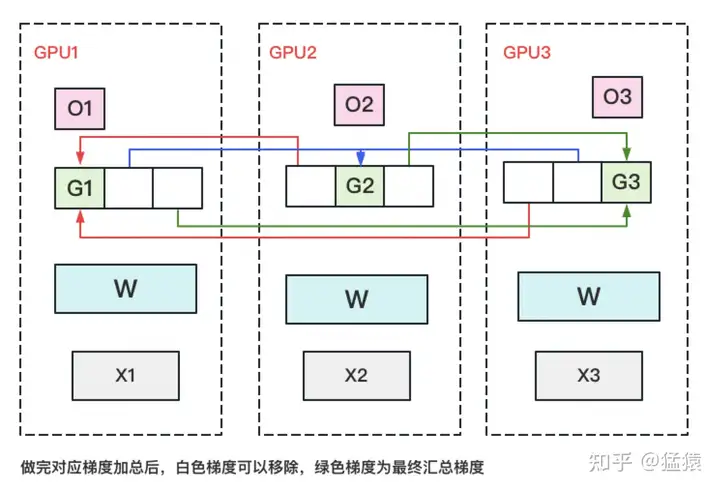
优化状态与梯度分割
把梯度也拆开,每个GPU格子维护一块梯度。
此时,数据并行的整体流程如下:
对梯度做一次 Reduce-Scatter ,保证每个GPU上所维持的那块梯度是聚合梯度。例如对GPU1,它负责维护G1,因此其他的GPU只需要把G1对应位置的梯度发给GPU1做加总就可。
每块GPU用自己对应的O和G去更新相应的W。更新完毕后, 每块GPU维持了一块更新完毕的W 。同理,对W做一次 All-Gather ,将别的GPU算好的W同步到自己这来。单卡通讯量 Φ 。

优化状态、梯度与参数分割
每块GPU只维持对应的optimizer states,gradients和parameters
- 做forward时,对W做一次 All-Gather ,取回分布在别的GPU上的W,得到一份完整的W,立刻把不是自己维护的W抛弃。
- 做backward时,对W做一次 All-Gather ,取回完整的W,**backward做完,立刻把不是自己维护的W抛弃。
- 做完backward,算得一份完整的梯度G,对G做一次 Reduce-Scatter ,从别的GPU上聚合自己维护的那部分梯度,聚合操作结束后,立刻把不是自己维护的G抛弃 。

到这一步, 我们用1.5倍的通讯开销,换回近120倍的显存 。只要梯度计算和异步更新做的好,通讯时间大部分可以被计算时间隐藏,因此这样的额外通讯开销,也是划算的。
ZeRO VS 模型并行
ZeRO是模型并行的形式,数据并行的实质 。
模型并行,是指在forward和backward的过程中,我只需要用自己维护的那块W来计算就行。即 同样的输入X,每块GPU上各算模型的一部分,最后通过某些方式聚合结果 。
对ZeRO来说,它做forward和backward的时候,是需要把各GPU上维护的W聚合起来的,即本质上还是用完整的W进行计算。 它是不同的输入X,完整的参数W,最终再做聚合 。
ZeRO-Offload与ZeRO-Infinity
核心思想是: 显存不够,内存来凑
把要存储的大头卸载(offload)到CPU上,而把计算部分放到GPU上
ZeRO-Offload的做法是:
- forward和backward计算量高 ,因此和它们相关的部分,例如参数W(fp16),activation,就全放入GPU。
- update的部分计算量低 ,因此和它相关的部分,全部放入CPU中。例如W(fp32),optimizer states(fp32)和gradients(fp16)等。
具体切分如下图:
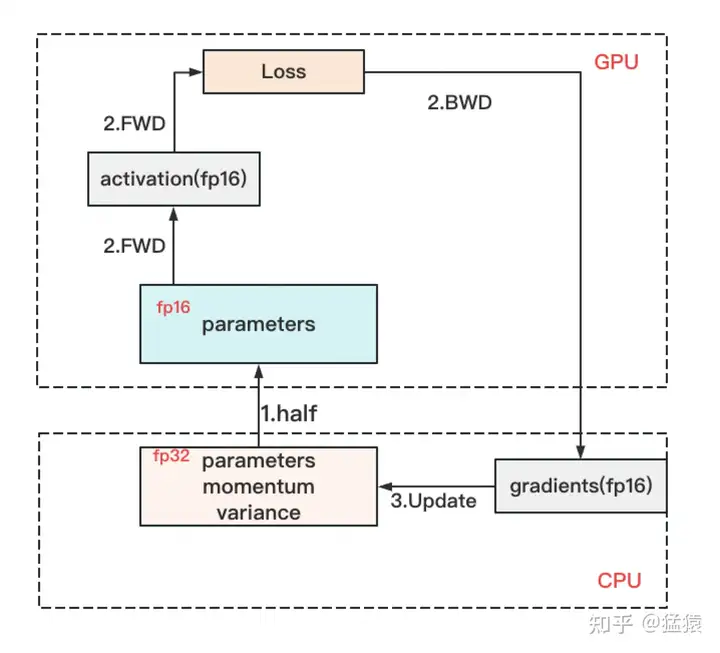
ZeRO-infinity也是同理,它们在解决的事情都是:找个除GPU之外的地方,存数据。感兴趣的朋友可以深入研究,这里就不展开了。
张量模型并行
把模型的参数纵向切开,放到不同的GPU上进行独立计算,然后再做聚合。
假设现在W太大,导致单卡装不下。我们需要把W切开放到不同的卡上,则我们面临三个主要问题:
- 怎么切分W。
- 切完W后,怎么做forward。
- 做完forward后,怎么做backward,进而求出梯度,更新权重。
按行切分权重
forward
我们用N来表示GPU的数量。有几块GPU,就把W按行维度切成几份。下图展示了N=2时的切割方式:
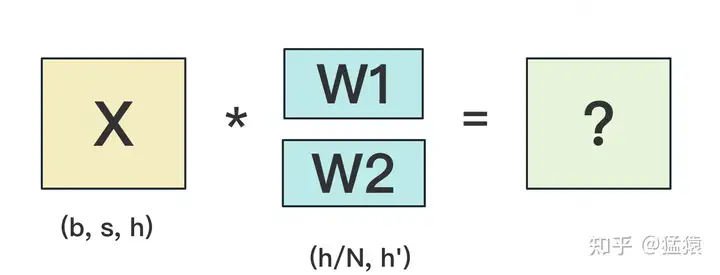
W按照行维度切开后,X的维度和它不对齐了,这可怎么做矩阵乘法呢?很简单,再把X“按列切开”就行了,如下图所示:
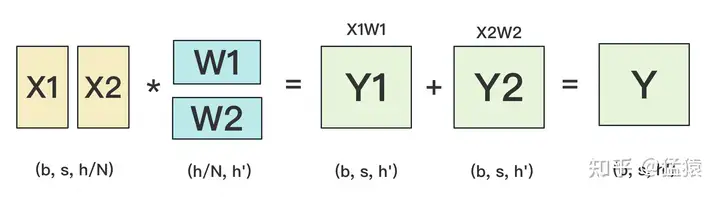
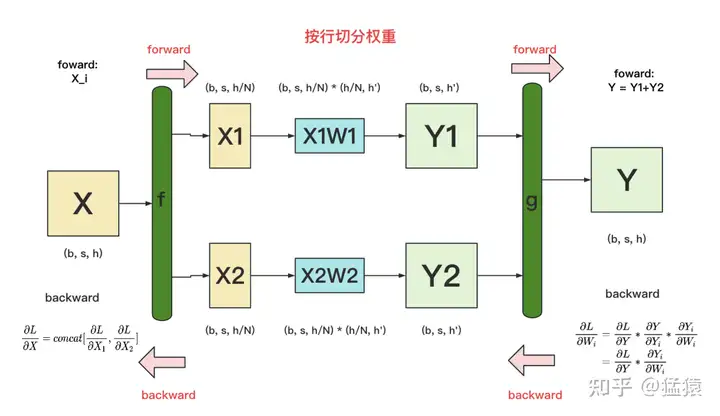
backward
做完forward,取得预测值Y,进而可计算出损失L,接下来就能做backward了。我们重画一下forward的过程,并在其中加入backward的部分,整体流程图如下:
按列切分权重
forward
按列切分权重后,forward计算图如下:
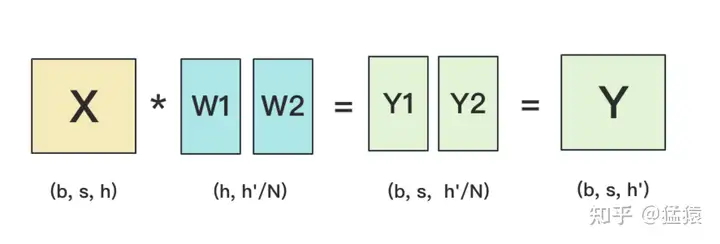
backward
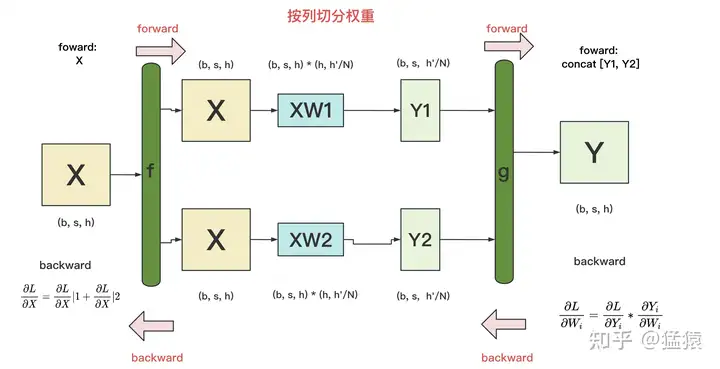
具体模型拆分方式:https://zhuanlan.zhihu.com/p/622212228
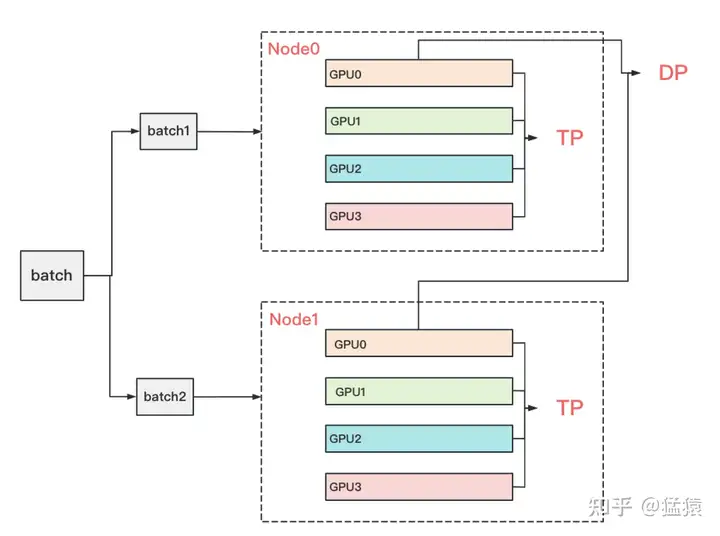
在实际应用中,对Transformer类的模型,采用最经典方法是张量模型并行 + 数据并行,并在数据并行中引入ZeRO做显存优化。具体的架构如下:
其中,node表示一台机器, 一般我们在同一台机器的GPU间做张量模型并行。在不同的机器上做数据并行 。图中颜色相同的部分,为一个数据并行组。凭直觉,我们可以知道这么设计大概率和两种并行方式的通讯量有关。具体来说, 它与TP和DP模式下每一层的通讯量有关,也与TP和DP的backward计算方式有关。