Stance Detection
立场检测相关内容总结整理
数据集
SemEval 2016
论文:Stance and Sentiment in Tweets
数据集可视化:http://www.saifmohammad.com/WebPages/StanceDataset.htm
VAST
Zero-shot数据集
New data released in this submission. Short column descriptions
- author: username of the comment author
- post: original comment, unprocessed
- ori_topic: heuristically extracted topic
- ori_id: id generated to link post and heuristically extracted topics
- new_topic: updated topic from crowdsourced annotations
- label: stance label, 0=con, 1=pro, 2=neutral
- type_idx: type number, 1=HeurTopic, 2=CorrTopic, 3=ListTopic, 4=Synthetic neutral
- new_id: unique id for every comment-topic-label pair
- arc_id: id of the original article on NYT
- text: sentence and word tokenized and lowercased text, with punctuation and stopwords removed
- text_s: string version of text
- topic: tokenized and lowercased version topic, with punctuation and stopwords removed
- topic_str: string version of topic
- seen?: indicator for zero-shot or few-shot example, 0=zero-shot, 1=few-shot
- contains_topic?: indicator for whether topic is contained in the text, 0=no, 1=yes
- change_lst: list of swapped words (unique to vast_test-sentswap.csv)
- change_type: type of sentiment swapping
- LexSim: a list of lexically similar training topics (if a zero-shot topic)
- Qte: whether the example contains quotes (1=yes, 0=no)
- Sarc: whether the example contains sarcasm (1=yes, 0=no)
- Imp: whether the text contains the topic and the label is non-neutral (1=yes, 0=no)
- mlS: whether there are other examples with the same document and different, non-neutral, stance labels (1=yes, 0=no)
- mlT: whether there are other examples with the same document and different topics (1=yes, 0=no)
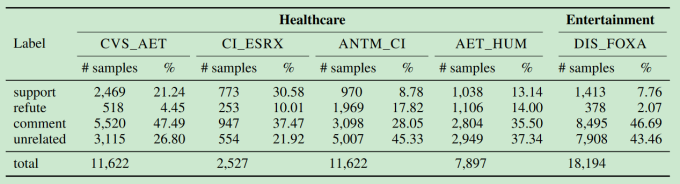
WT-WT
相关链接:https://github.com/BinLiang-NLP/TPDG
51284条英文Tweet
关于公司的兼并收购的信息,第一个金融领域的数据集
四个标签:
- Support:两个公司会合并成一个公司
- Refute:对两个公司要合并成一个的消息表示怀疑
- Comment:对合并消息的评论,中立态度
- Unrelated:完全不相关
P-stance
21574条英文Tweet
对三个target(Donald Trump(7953),Joe Biden(7296),Bernie Sanders(6325))的立场
按照8:1:1进行划分
UKP
论文
2017
A Dataset for Multi-Target Stance Detection
时间:2017年4月
等级:EACL 2017
2020
Will-They-Won’t-They: A Very Large Dataset for Stance Detection on Twitter
时间:2020年5月1日
等级:ACL 2020
思想:
- 第一个金融领域的立场数据集,描述公司的兼并收购的信息
- 首先爬取关于公司、兼并等内容的Tweet
- 定义四个标签(support, refute, comment, unrelated),其中一个Tweet的不同的target可能会有不同的标签
- 找人进行标注,评估了标注的质量,并与之前的数据集进行了对比
- 对目前的一些模型进行了这个数据集上面的测试
Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations
时间:2020年10月7日
等级:EMNLP 2020(CCF B)
思想:提出了VAST数据集
- 纽约时报辩论区的评论内容
- 选择了3365条评论,包括304个主题,找人工进行主题标注
- 中立的立场很少,从支持与反对两种类别中选一些可能性较低的加入到中立标签中
同时提出了一个方法解决Zero-shot问题
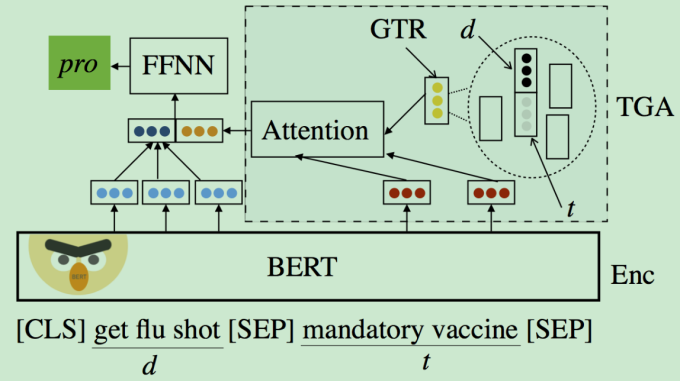
- 文档和主题联合输入
- 对主题进行聚类,获取注意力
数据集:VAST
2021
Target-adaptive Graph for Cross-target Stance Detection
时间:2021年4月
等级:WWW 2021(CCF A)
tWT–WT: A Dataset to Assert the Role of Target Entities for Detecting Stance of Tweets
时间:2021年6月
等级:NAACL 2021(CCF B)
Adversarial Learning for Zero-Shot Stance Detection on Social Media
时间:2021年6月
等级:NAACL 2021(CCF B)
思想:使用对抗学习增强zero-shot的立场检测的效果
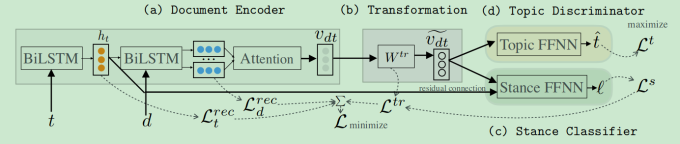
- 使用BiCond编码text
- 将编码的向量进行正则化
- 对立场进行分类
- 对topic进行鉴别
- 增加对抗训练的技巧
数据集:Sem-16
Stance Detection in COVID-19 Tweets
时间:2021年8月
等级:ACL 2021(CCF A)
思想:
- 构建了一个COVID-19数据集,包括四个target,例如关闭学校、居家、戴口罩等
- 用无标签的数据做预训练
- 对不同的监督学习方法进行了比较
数据集:自行构建的COVID-19数据集
Enhancing Zero-shot and Few-shot Stance Detection with Commonsense Knowledge Graph
时间:2021年8月
等级:ACL 2021 Findings (CCF A)
思想:topic在文本中是可以通过图推断出来的
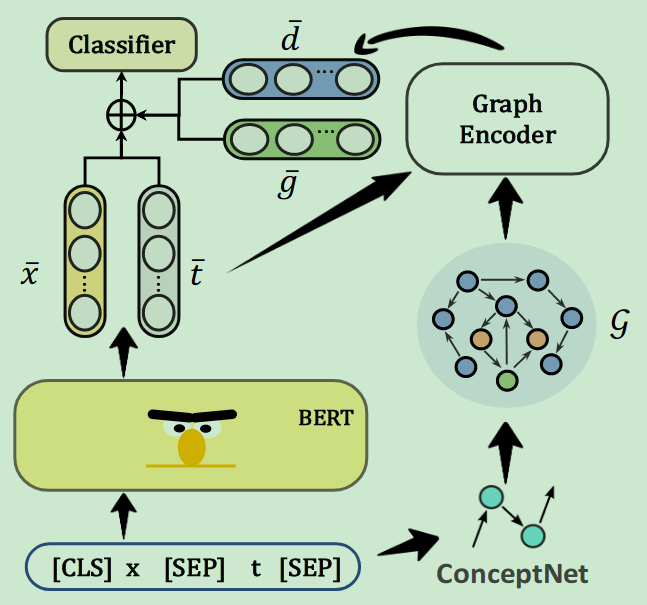
- 用Bert对文本和topic进行编码
- 使用ConceptNet获取文本之间的关系
- 进行立场分类检测
数据集:
MeLT: Message-Level Transformer with Masked Document Representations as Pre-Training for Stance Detection
时间:2021年09月16日
等级:EMNLP 2021 Findings
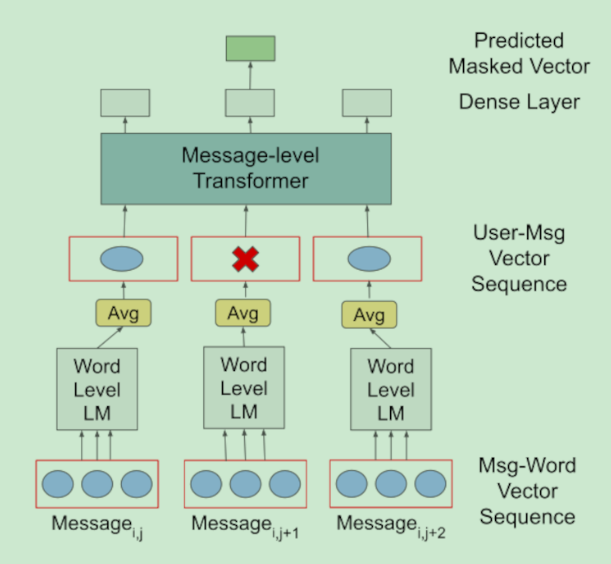
思想:
- 在Twitter数据集上做预训练,将word级别的mask更改为message级别的mask,message的表示是word的表示取平均,按照时间顺序进行排列,对某个人的一些message进行随机mask(Bert的方式),让模型预测该位置的message。
- 后续进行分类任务的微调
数据集:SemEval 2016
P-Stance: A Large Dataset for Stance Detection in Political Domain
时间:2021年08月
等级:ACL 2021 Findings
思想:
- 现有数据集局限
- 明确提及的目标和可能暴露立场的表层词汇线索在数据中显式存在
- 社交媒体的数据太短了,模型不需要理解就可以找出立场
- 通过#的标签收集三个总统候选人的Tweet,收集了2.8 million条数据
- 选取10-128长度的Tweet
- 移除重复数据
- 只保留英文数据
- 减少到2 million,为PSTANCE-EXT数据
- 每个人采样10000,共30000条数据构成最终的数据集
- 人工标注,并去除I don’t know类别的数据
- 构建一个#词典,删除文本后面的#,同时更改内部的#为中性的标记,防止暴露立场信息
- 微调BERTweet预测CLS进行分类任务
- 可以进行跨目标的立场检测、跨主题的立场检测(在2016年的数据上训练,预测2020年的立场)
- 采用半监督方法(UST)提升跨主题的立场检测性能(没详细介绍)
数据集:SemEval-2016、Multi-Target stance datasets
2022
Zero-Shot Stance Detection via Contrastive Learning
时间:2022年4月
等级:WWW 2022(CCF A)
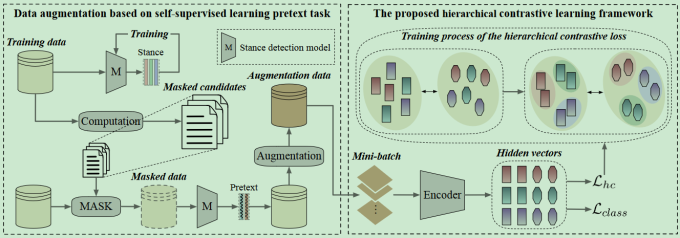
思想:
- 将数据分为两种类型:
- target-invariant:即使目标或目标相关词被屏蔽,仍然可以识别上下文中表达的立场。
- target-specific:如果目标和与目标相关的词语被屏蔽,则很难理解立场信息。
- 训练一个普通的立场检测模型,训练到过拟合
- 用主题模型找到与target最相关的词语,然后将其MASK掉,用上面的模型进行预测。如果预测对了就是target-invariant,错了就是target-specific,加一个标签给这个数据
- 重新训练主模型
- target-invariant与target-specific之间作对比学习
- 不同的label之间做对比学习
- 数据集: VAST、SEM-16、WT-WT
Infusing Knowledge from Wikipedia to Enhance Stance Detection
时间:2022年5月
等级:ACL 2022 Workshop(WASSA)
思想:从Wikipedia上预先查询到target的相关知识,融合到模型中进行立场检测
数据集:P-Stance、COVID-19-Stance、VAST
Few-Shot Stance Detection via Target-Aware Prompt Distillation
时间:2022年6月27日
等级:SIGIR 2022(CCF A)
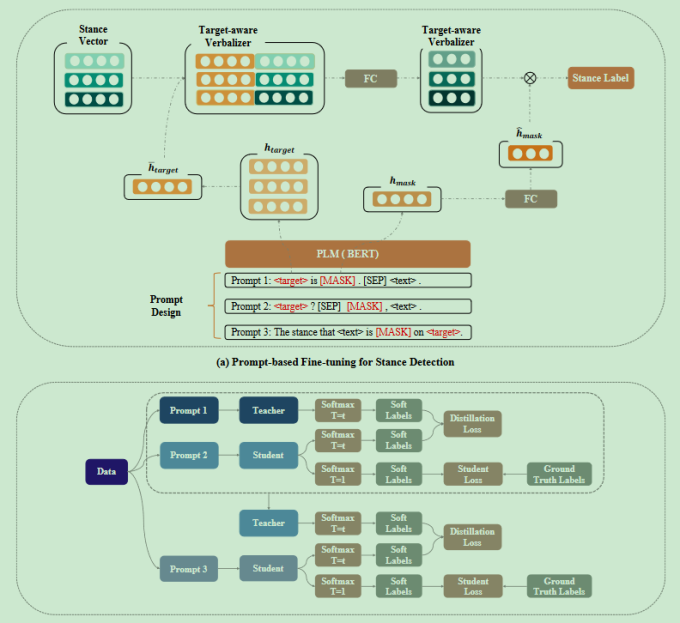
思想:
- 动机:target通常是随时间变化的,对每一个target都获取充足的数据进行训练是很不现实的,立场检测方法需要获得few-shot的能力
- 多目标训练:训练一个模型,可以准确预测不同的target的label
- 设计三个Prompt,输入到Bert等模型的预训练任务中,让其预测label
- 预测的时候不映射到具体的label的词语,而是提前通过预训练模型获取label的表示向量,最终将target的向量与label的向量相乘计算损失
- teacher-student model融合三个prompt的结果,迭代进行预测,对比真实标签与预测标签之间的差距。
数据集:SemEval-2016、UKP
JointCL: A Joint Contrastive Learning Framework for Zero-Shot Stance Detection
时间:2022年5月
等级:ACL 2022(CCF A)
思想:
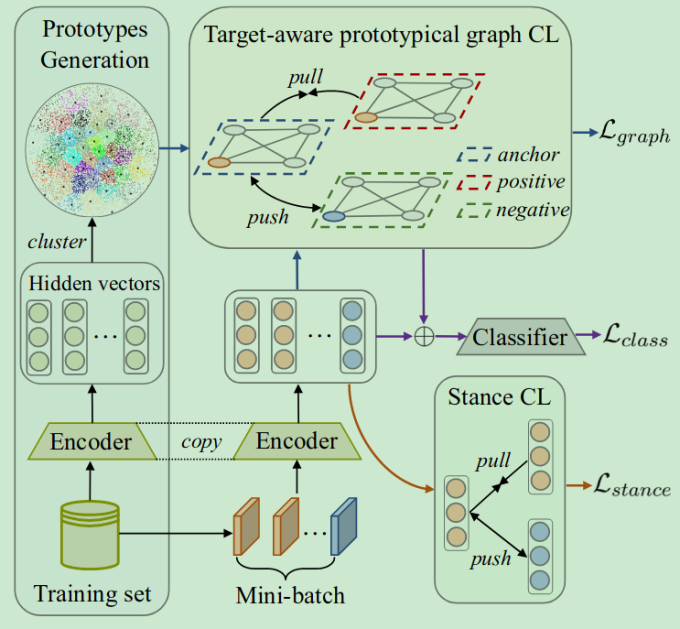
图相关
- 一个没有出现过的target的信息是可以通过其他已知的target表示出来的(从target-aware的视角来看)
- 提出了由立场对比学习与原型图网络对比学习。通过构建原形图,可以在未知target和已知target之间建立关系,从而用已学习到的信息表示未知target,从而提升对未知target的立场学习能力。
数据集:VAST、SEM-16、WT-WT
A Survey on Stance Detection for Mis- and Disinformation Identification
时间:2022年7月
等级:NAACL 2022 Findings(CCF B)
思想:虚假新闻的立场检测,一篇综述性质的文章
数据集:没有做实验,只是汇总之前人的数据、方法与结果
Enhancing Zero-Shot Stance Detection via Targeted Background Knowledge
时间:2022年7月
等级:SIGIR 2022(CCF A)

思想:
- 用相关信息进行增强
- 根据target在网络上爬取相关信息,找最相关的top k个主题
- 用NLTK的工具提取关键词,找到爬取的信息中与关键词最相关的部分,作为额外知识
- 其他的模型训练非常普通
数据集:VAST、SEM-16、WT-WT
Exploiting Sentiment and Common Sense for Zero-shot Stance Detection
时间:2022年10月
等级:COLING 2022
思想:
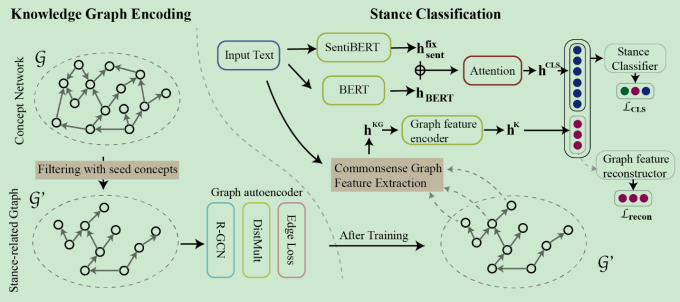
图相关
- 使用图自动编码的模块将target的普遍信息融合进立场检测的模型
- 立场检测是被情感词汇影响的,使用Bert单独提取文档中的情感的词汇。
Generative Data Augmentation with Contrastive Learning for Zero-Shot Stance Detection
时间:2022年12月
等级:EMNLP 2022(CCF B)
思想:在看见过的target的基础之上生成没有看见过的target的数据
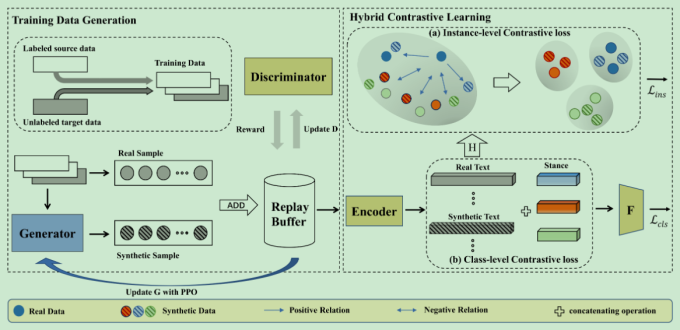
- 使用GAN网络进行对抗生成
- 添加对比学习的策略
- 在立场检测任务上进行微调
数据集:VAST、Sem-16
How would Stance Detection Techniques Evolve after the Launch of ChatGPT?
时间:2022年12月30日
等级:Arxiv
思想:
- 加个Prompt的立场检测效果可以达到SOTA
- 多轮对话理论上可以增强背景知识等
- 没有和很多的SOTA进行比较,没啥说服力
数据集:P-Stance
2023
Hashtag-Guided Low-Resource Tweet Classification
时间:2023年2月20日
等级:WWW 2023(CCF A)
思想:
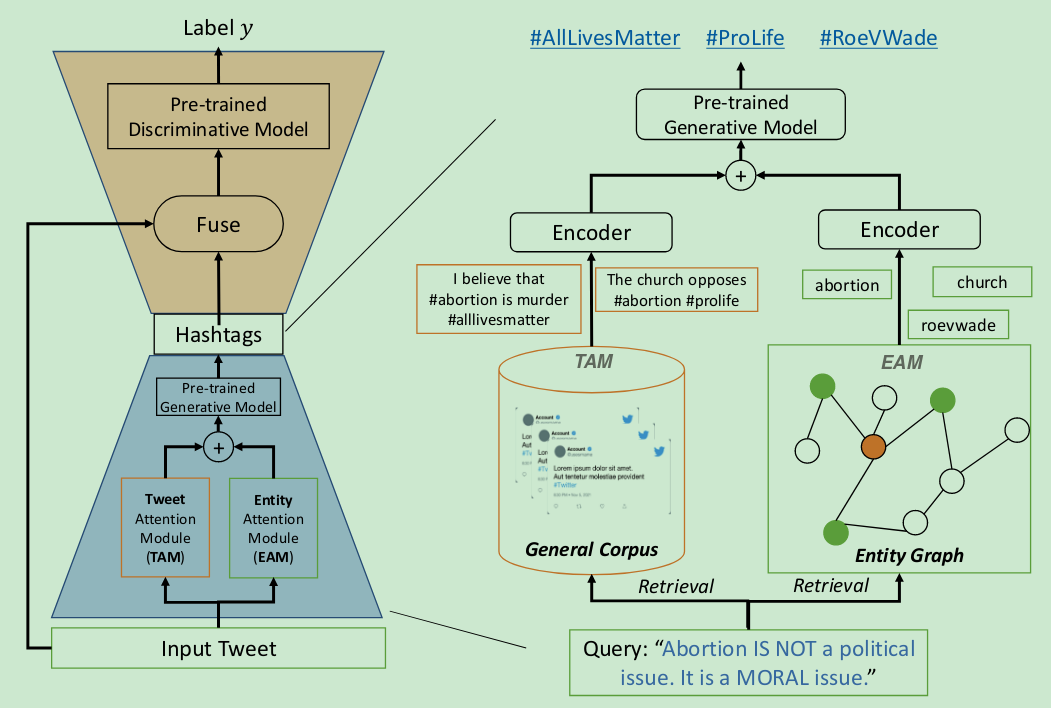
- Hash Tag是很重要的
- Tweet注意力模块:获取Tweet之间的相关性从而借鉴已有的标签
- 实体注意力模块:实体图获取Tweet中的实体
- 融合两个模块生成HashTag
- 通过原始的Tweet与HashTag一起输入到预训练模型中进行训练
数据集:
Few-shot Learning for Cross-Target Stance Detection by Aggregating Multimodal Embeddings
时间:2023年3月31日
等级:IEEE Transactions on Computational Social Systems(CCF C)
思想:
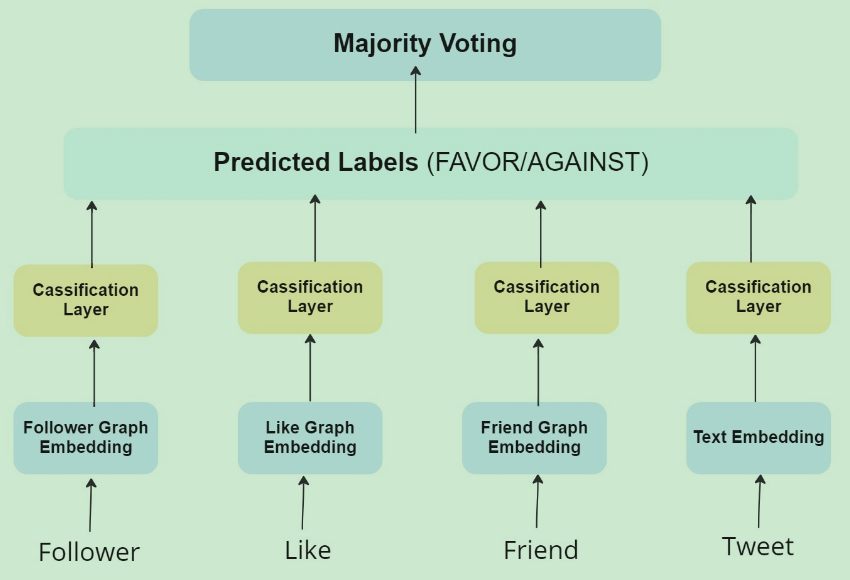
- 通过发Tweet的人之间的关系网络增强立场检测的效果
- 包括Follower、Like和Friend的信息
数据集:P-Stance,额外找到了作者的关系信息
Investigating Chain-of-thought with ChatGPT for Stance Detection on Social Media
时间:2023年4月6日
等级:Arxiv
思想:通过思维链的方式,给一个例子帮助ChatGPT进行分析,在多个数据集上达到了SOTA(假)效果
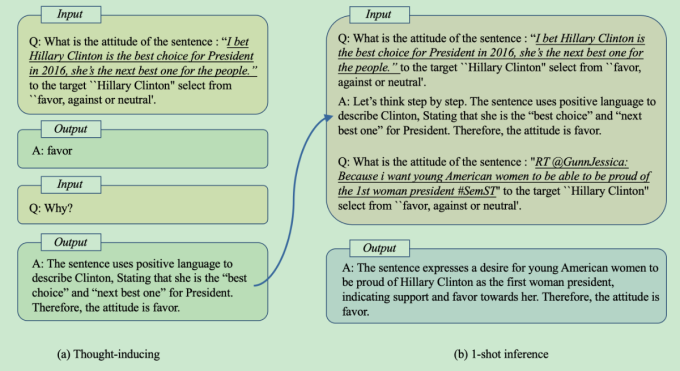
数据集:SEM-16、VAST、P-Stance
Claim Extraction and Dynamic Stance Detection in COVID-19 Tweets
时间:2023年4月
等级:WWW 2023 Companion
思想:
- 是否存在主张:作者是否在Tweet中提出了客观事实的主张?并进一步分析是否值得检查。
- 微调Bert系列的模型来完成
- 主张提取:识别Tweet中的哪些部分对应于事实主张,哪些部分对应于作者的评论
- 使用IOB2方式进行标注,也是微调Bert进行,尝试了多种模型结构
- 动态立场检测:识别作者对事实主张的立场。不过主张是上面识别出来的,因此变化很大,基本上之前都没有见过
- 数据集:自行收集的COVID-19的数据集
Can ChatGPT Reproduce Human-Generated Labels? A Study of Social Computing Tasks
时间:2023年4月22日
等级:无
思想:
- 将一些NLP任务的数据集通过ChatGPT进行标注,标注后评估效果
- 在立场检测的任务上面大概0.5-0.6左右
Examining Temporalities on Stance Detection Towards COVID-19 Vaccination
时间:2023年5月7日
等级:ICWSM Data Challenge
思想:
- 划分数据集是以时间顺序进行划分的,更接近于真实的情况
- 用单语言的Bert和多语言的Bert进行测试
数据集:COVID数据集
Robust Integration of Contextual Information for Cross-Target Stance Detection
(Contextual information integration for stance detection via cross-attention)
时间:2023年5月25日
等级:SEM2023(Co-located with ACL 2023)
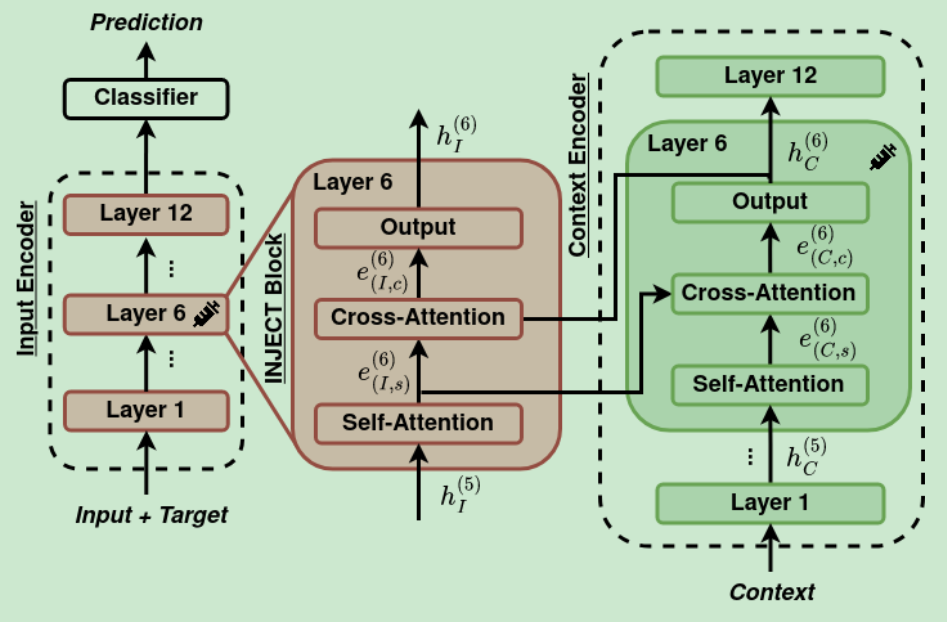
思想:
- 一个灵活的结合外部知识的方法
- 一个Input+Target的Encoder和另外一个Context的Encoder,相当于Cross Attention
- 直接连接Context与Text,相当于Self Attention
- 尝试了多种获取外部知识的方法。例如ConceptNet、CauseNet、预训练模型等
- 多个数据集测试效果
Guiding Computational Stance Detection with Expanded Stance Triangle Framework
时间:2023年5月31日
等级:ACL 2023
思想:
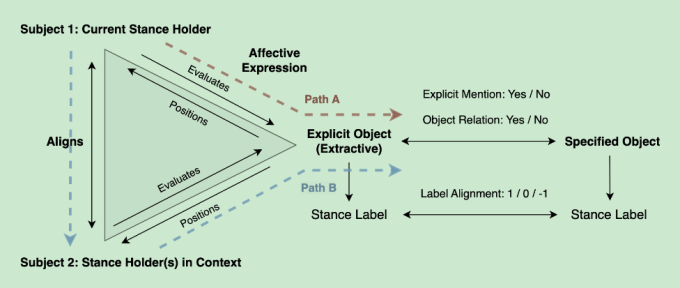
- 从语言学的角度考虑立场检测,使用很早就提出过的立场检测三角形
- 语言学看不太懂,效果也没有很SOTA
- 感觉就是方法比较新颖
数据集:SEM-16、P-Stance、VAST、Tweet-COVID
Knowledge-enhanced Prompt-tuning for Stance Detection
时间:2023年6月
等级:2023 ACM Transactions on Asian and Low-Resource Language Information Processing(SCI 4区 CCF C)
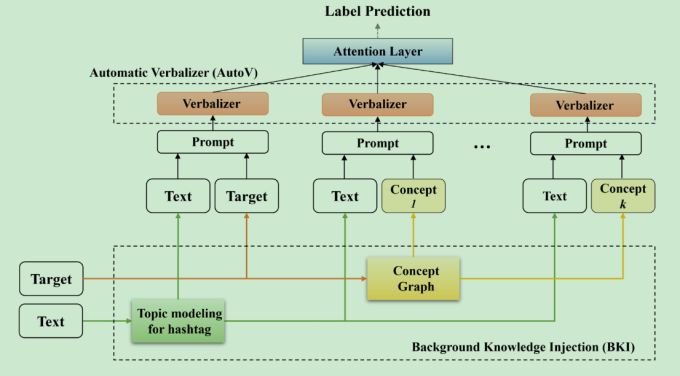
思想:
- 将立场检测的任务通过Bert中MASK的方式转换成一个MLM任务
- 自动空间映射器:用SenticNet扩充词汇,自动选择相关的词语进行答案的映射(涉及一个树模型)
- 背景知识
- 将target送入ConceptGraph中获得target的背景知识
- 使用neural topic model学习利用#符号的语义信息(涉及变分自编码器VAE)
- 将上述的知识一起作为Prompt送入到预训练模型中进行微调,得到类别
数据集:SEM16、VAST、P-stance、自己的数据集(ISD)
Topic-Guided Sampling For Data-Efficient Multi-Domain Stance Detection
时间:2023年6月
等级:ACL 2023 Oral(CCF A)
思想:
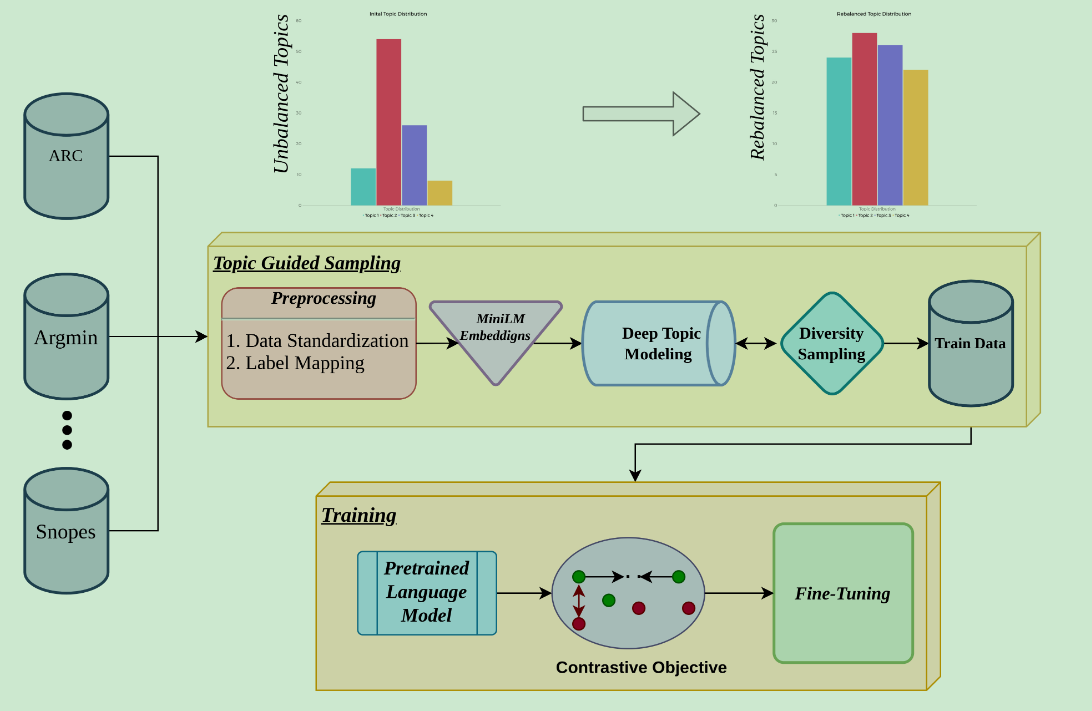
- 适用于跨主题(领域)的立场检测
- 方法
- 通过主题模型进行训练数据的采样
- 将立场检测看成序列分类问题(d, t),加个Prompt
- 对比学习计算损失
数据集:16个benchmark数据集
Voting Booklet Bias: Stance Detection in Swiss Federal Communication
时间:2023年6月15日
等级:Arxiv
思想:
- 分析的目标是面向选民的小册子中的Topic的立场是否为中立的立场
- 模型结构没有创新,评价了一些方法的性能
- 这个任务与普通的立场检测任务不同
数据集:x-stance
C-STANCE: A Large Dataset for Chinese Zero-Shot Stance Detection
时间:2023年7月
等级:ACL 2023(CCF A)
思想:第一个中文的Zero-shot数据集
- 微博的数据
- 人工进行标注
- 在多个立场检测的领域,使用多种方法进行评测
数据集:C-STANCE
A New Direction in Stance Detection: Target-Stance Extraction in the Wild
时间:2023年7月
等级:ACL 2023(CCF A)
思想:
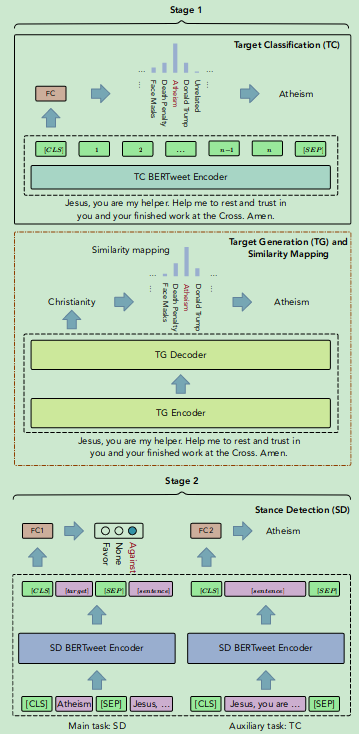
- 在立场检测中,target可能是隐含在text中的,大规模标注target不太现实
- 从文本中获取target-stance的对
- Target Identification:
- 训练一个分类器对target进行分类
- 用BART对target进行生成,然后map到已知的target上面
- Stance Detection
- 建立一个分类器,并用target预测作为辅助任务
数据集:SemEval-2016、AM、COVID-19、P-Stance、自己构建的zero-shot数据集
Distilling Calibrated Knowledge for Stance Detection
时间:2023年7月
等级:ACL 2023 Findings(CCF A)
思想:与知识蒸馏等相关
数据集:AM、COVID-19、P-Stance
Target-Oriented Relation Alignment for Cross-Lingual Stance Detection
时间:2023年7月
等级:ACL 2023 Findings(CCF A)
思想:将单语言的立场检测迁移到多语言上
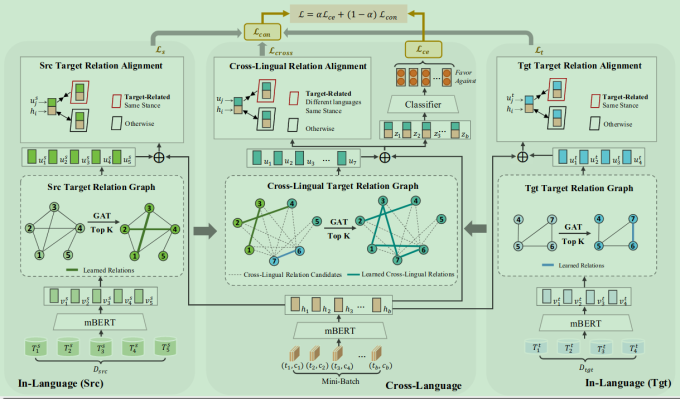
- 使用mBert获取文本的表示
- 构建target的关系图
也是图相关的工作
数据集:X-Stance-all
Exploration of Contrastive Learning Strategies toward more Robust Stance Detection
时间:2023年7月
等级:ACL 2023 Workshop(WASSA)
思想:使用对比学习增强立场检测系统的鲁棒性
- 词表相似的句子也能通过对比学习获取语义从而发现他们之间的区别
- 选择anchor的策略可以有多种方法
- 使用拼写错误、同义重复和同义词替换三种策略来对数据集进行增强
- 不同的构造方法(数据集中的所有topic或者一部分的topic)进行不同的数据集下的训练,仅考虑二分类
数据集:DebateForum (DF), SemEval2016 (SE) ,ARC, Perspectrum, FNC-1, KSD-Biden, KSD-Trump
Zero-Shot and Few-Shot Stance Detection on Varied Topics via Conditional Generation
时间:2023年7月
等级:ACL 2023(CCF A)
思想:
- 用生成的思想做立场检测的问题,使用BART作为基础架构
- 使用联合训练,不仅生成标签,同时生成target
- Unlikelihood Training 数据增强方法提升性能
- 结合Wiki的知识(其他论文的工作)
数据集:VAST
Ladder-of-Thought: Using Knowledge as Steps to Elevate Stance Detection
时间:2023年8月31日
等级:Arxiv
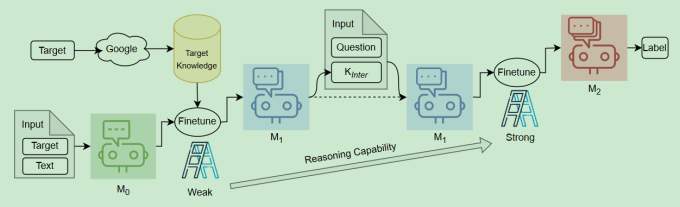
思想:
- CoT利用的是大模型内部的知识,但是立场检测相关的知识大模型可能没有见过
- 首先在Google上面搜到target的相关信息
- 用Text,Target和上面搜集到的信息微调一个预训练模型,让其产生更好的外部信息 Generation Finetuning
- 在上面的模型基础上,将text,target,和上面产生的外部信息连接在一起输入到模型中,以预测label为目标进行微调
数据集:VAST
Use of Large Language Models for Stance Classification
时间:2023年9月24日
等级:ICWSM 2024 (CCF B)
思想:
- 尝试了四种Prompt,用上下文包裹text和target,加一些few shot的例子,最后让其解释原因
- 尝试了几种开源的大模型
- 总结:大模型不太行,不如微调过的小模型,甚至不如zero-shot
数据集:covid-lies、election2016、phemerumors、semeval2016、wtwt
STANCE-C3: Domain-adaptive Cross-target Stance Detection via Contrastive Learning and Counterfactual Generation
时间:2023年9月26日
等级:无
思想:
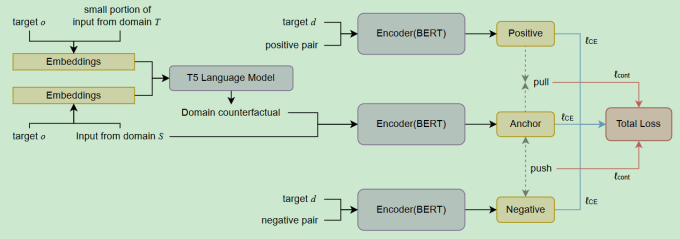
- 跨领域的知识迁移
- 反事实数据增强
StanceReCL: Zero-Shot Stance Detection Based on Relevance and Contrastive Learning
时间:2023年10月
等级:投稿 EMNLP 2023 没中
思想:
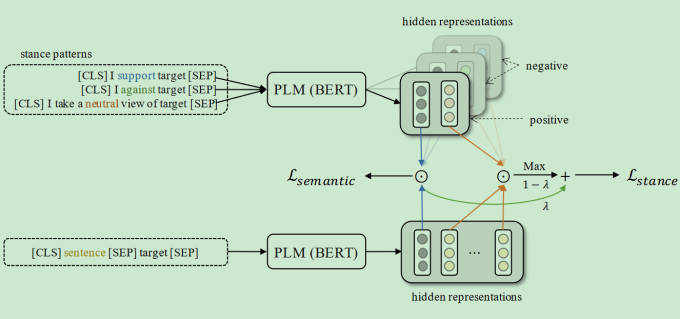
- 提出了几个概念:stance indicator(support,against和neutral),stance pattern(由stance indicator和target组成)
- 两种表达:句子层面的表达([CLS]对应的最后一层的表示)与词语层面的表达(单个token的最后一层的隐藏状态)
- 相关性的计算:
- 上面的CLS与下面的CLS计算句子层面的相关性
- 上面的stance indicator与下面的sentence中的最相关的词语计算相关性
- 句子层面计算对比学习的损失,然后与词语层面的损失加权重融合计算
数据集:SEM-16、VAST、WT-WT
Stance Detection with Collaborative Role-Infused LLM-Based Agents
时间:2023年10月
等级:Arxiv
思想:多个LLM的Agent一起分析文本的各个方面,最后一正一反对立场进行推断,完全的Zero-shot
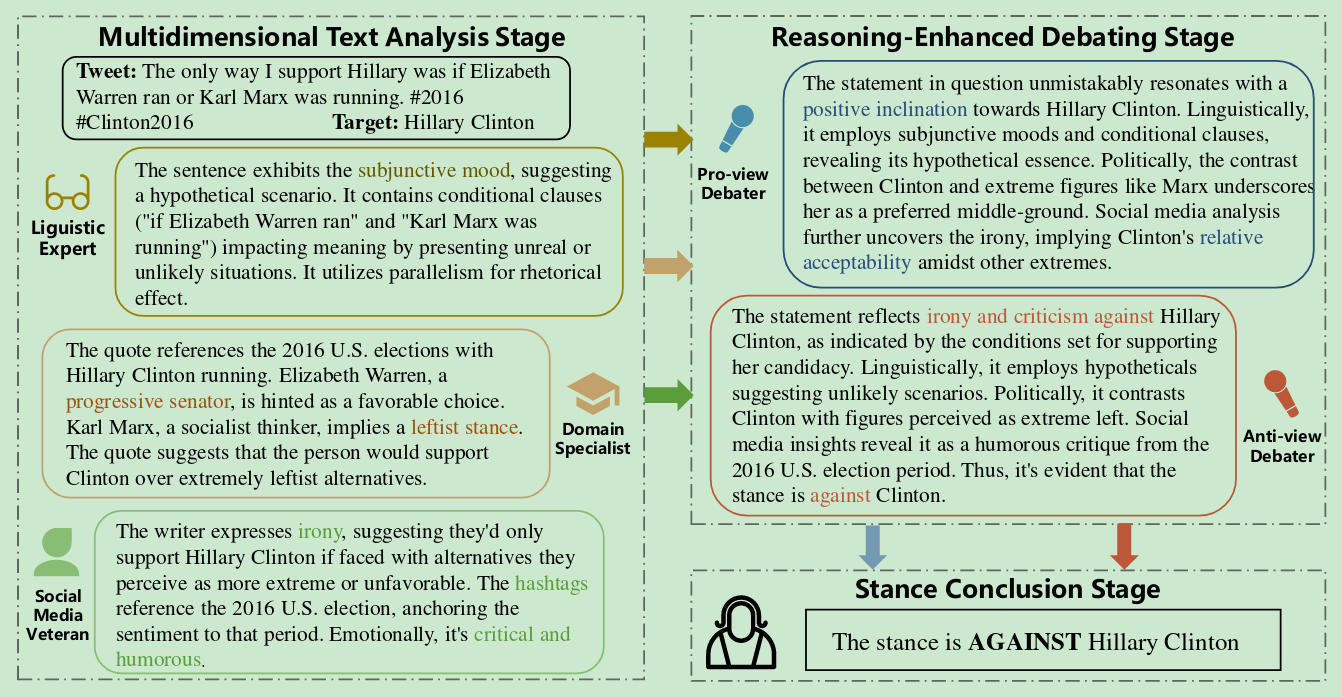
数据集:Sem-16、WT-WT、VAST
TATA: Stance Detection via Topic-Agnostic and Topic-Aware Embeddings
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:
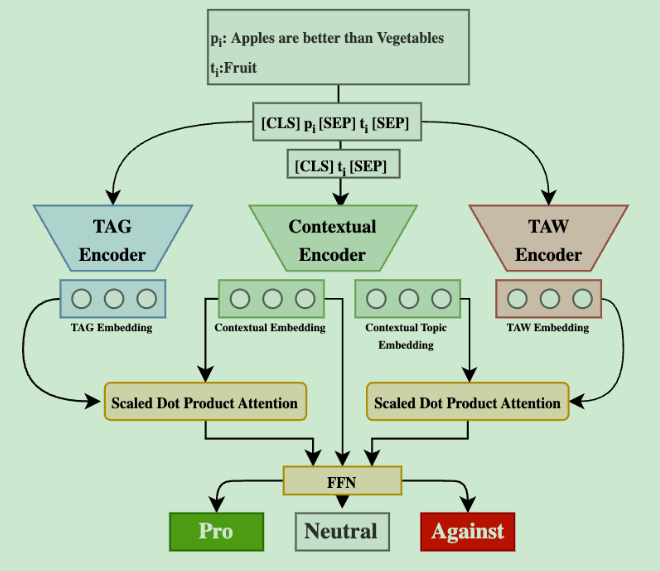
- topic-aware/TAW embeddings and generalized topic-agnostic/TAG stance embeddings
- 使用T5-Flan作为基座模型
- 收集了一个新的数据集,包括相关的passage对与相关的topic对,Topic-Aware/TAW Dataset
- 使用T5对topic进行预测从而做预训练任务
- 使用MPNet LLM 识别其他数据集中相同的topic
- 用TAW Dataset对VAST数据集进行扩充
- Topic-Aware/TAW Embedding Layer:对整个的text-topic对进行训练
- Topic-Agnostic/TAG Embedding Layer:topic看不到
- 后面加两个注意力层
数据集:VAST
Support or Refute: Analyzing the Stance of Evidence to Detect Out-of-Context Mis- and Disinformation
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:多模态的信息不匹配会造成误解
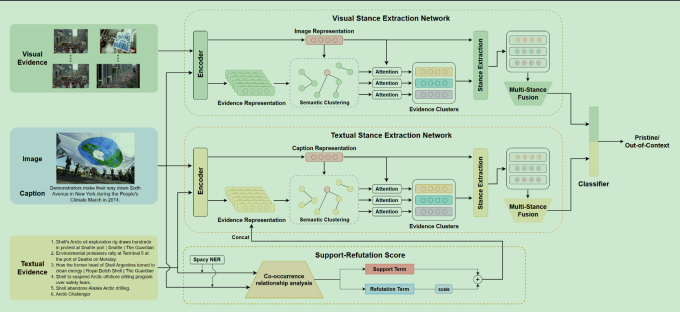
分别训练图片的立场检测分类器、文本的立场检测分类器,外加一些实体的知识进行识别
数据集:NewsCLIPpings
Why Should This Article Be Deleted? Transparent Stance Detection in Multilingual Wikipedia Editor Discussions
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:在文本审核中加入立场检测从而进行自动判断其是否应该被删除
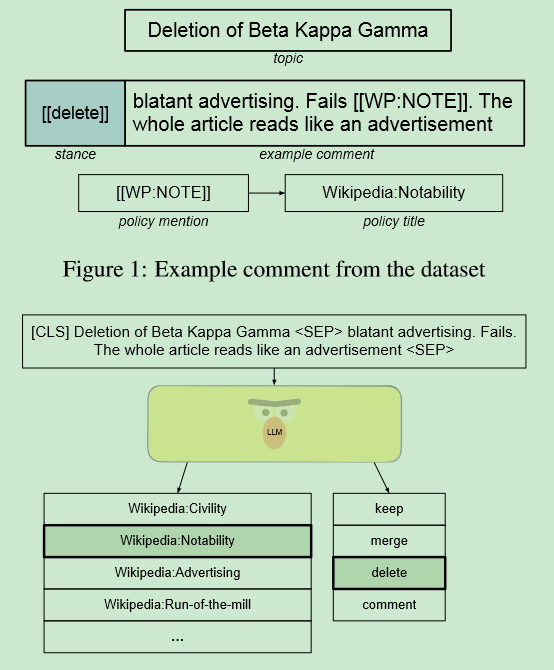
数据集:提出了多语言的Wiki的审核数据集
ORCHID: A Chinese Debate Corpus for Target-Independent Stance Detection and Argumentative Dialogue Summarization
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:
- 提出中文的辩论的立场检测数据集,且是与目标无关的
- 提出立场相关的摘要任务,可以提升摘要的效果
数据集:
Cross-Lingual Cross-Target Stance Detection with Dual Knowledge Distillation Framework
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:
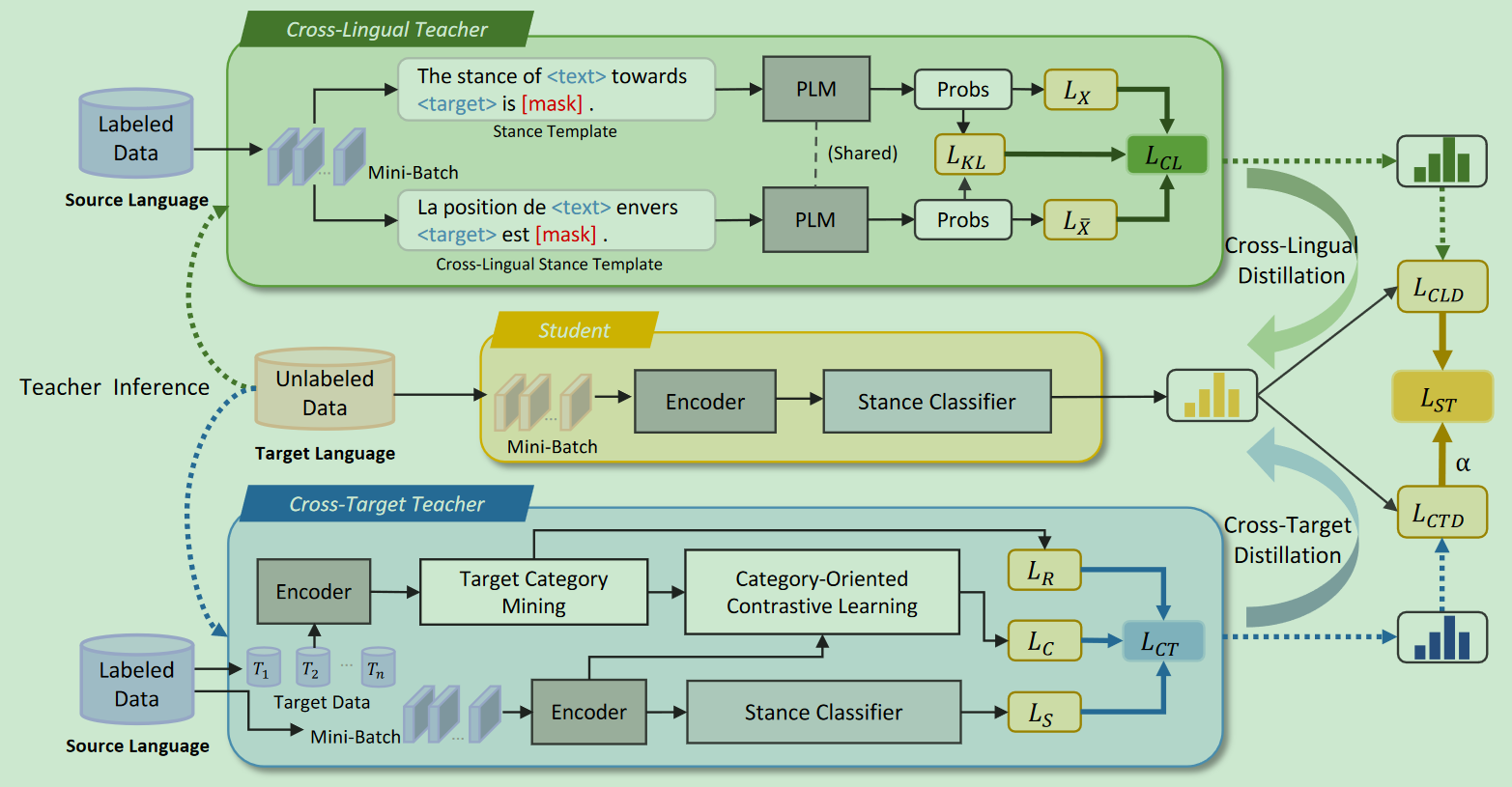
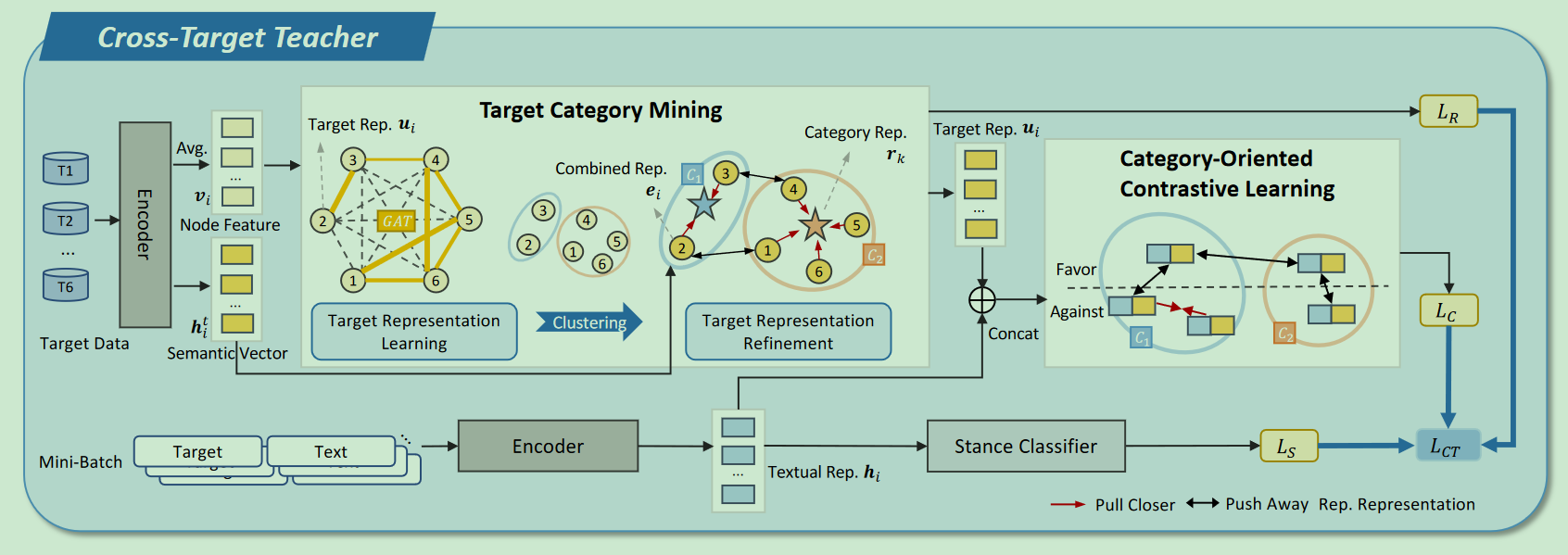
- 提出了新的跨语言cross target的立场检测任务
- 一个跨语言的老师,一个跨target的老师
- 大量的目标语言的无标签数据如何利用
- 使用mBert作为跨语言的teacher,翻译prompt和label构建文本对,使得两个文本对的预测结果更为接近
- 使用上面的跨语言的teacher作为跨target的encoder
- 使用GAT等将target分类,然后做与类别相关的对比学习
- 用无标签的目标语言数据+两个teacher的伪标签训练
数据集:X-Stance、Semeval-2016、R-ita、Czech
Identification of Multimodal Stance Towards Frames of Communication
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:文字和图片的多模态立场检测,主要的贡献是数据集
- 在疫苗场景下
- 收集了关于疫苗或者新冠的Twitter的数据集,包括文字与图片数据
- 选择了一些多模态的模型作为baseline,通过OCR等方式提取图片中的文字
- 分一些图片与文字不吻合的情况
数据集:MMVAX-STANCE
From Values to Opinions: Predicting Human Behaviors and Stances Using Value-Injected Large Language Models
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:与价值观相关,不算立场检测任务
- 使用Argument Generation和Question Answering两种方法对LLM进行微调
数据集:非立场检测
Stance Detection on Social Media with Background Knowledge
时间:2023年12月
等级:EMNLP 2023(CCF B)
思想:补充两种知识增强立场检测的效果
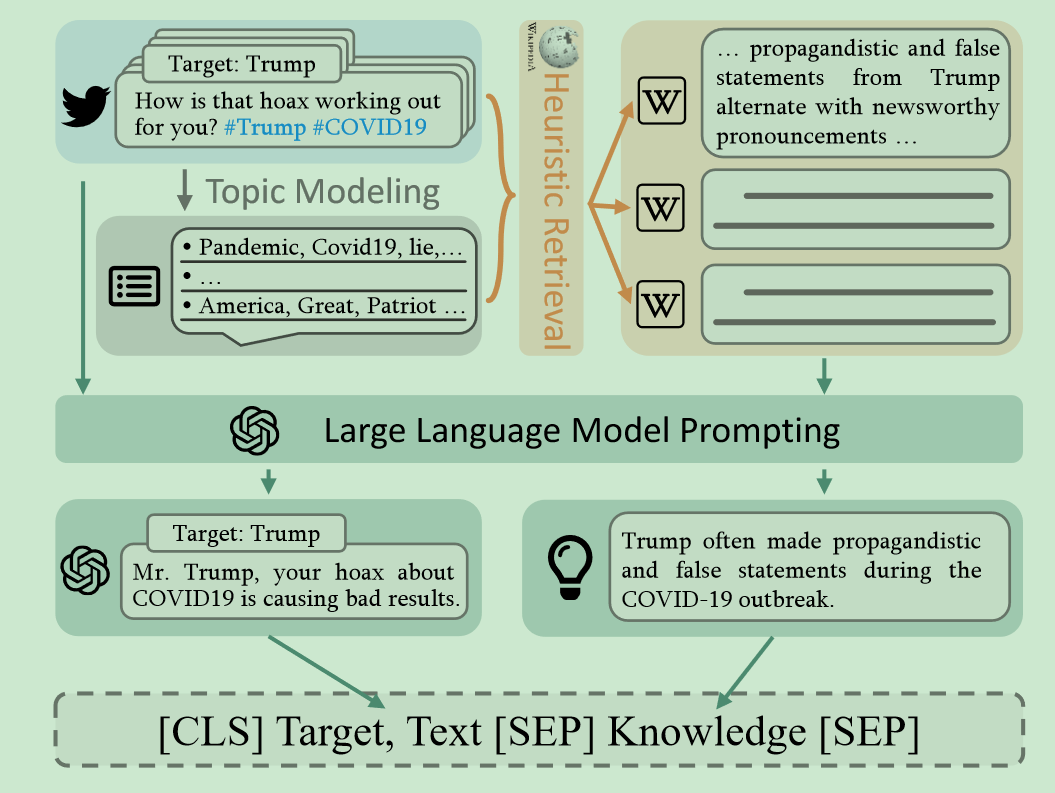
- Episodic knowledge:情景知识,只能从背景知识中推断出来
- discourse knowledge:口语知识,代号、hashtag等
- 在网络上搜索最相关的top10的wiki知识
- 通过主题模型和关键词检索最相关的部分、使用大模型进行过滤
- 使用大模型对口语知识进行扩充
- 既微调了小模型,也在大模型上面做zero-shot看效果
数据集:Sem-16、P-Stance、VAST
EZ-STANCE: A Large Dataset for Zero-Shot Stance Detection
时间:2023年12月
等级:EMNLP 2023 Findings
思想:提出了与VAST对标的EZ-Stance数据集
数据集:EZ-Stance
Multi-label and Multi-target Sampling of Machine Annotation for Computational Stance Detection
时间:2023年12月
等级:EMNLP 2023 Findings
思想:思维链等zero-shot来增强直接使用大模型进行立场检测的效果
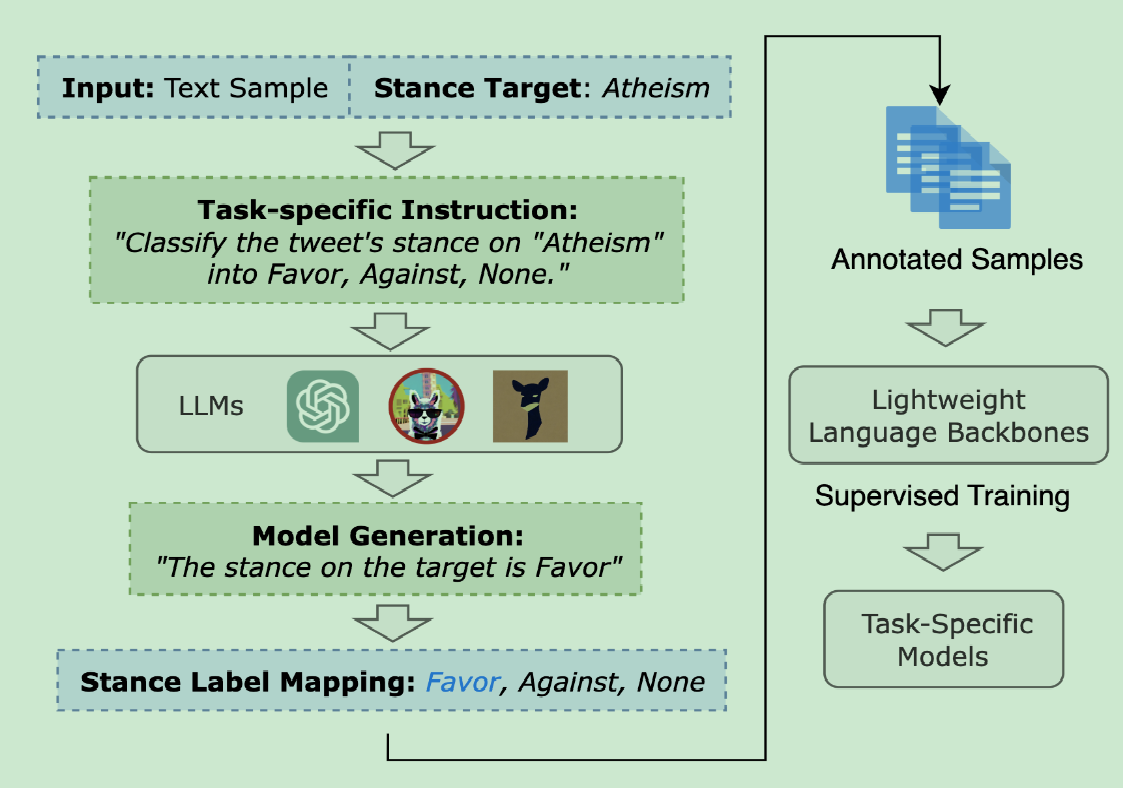
数据集:
Chain-of-Thought Embeddings for Stance Detection on Social Media
时间:2023年12月
等级:EMNLP 2023 Findings
思想:用大模型对立场进行预测,然后输入到Roberta中进行再次预测
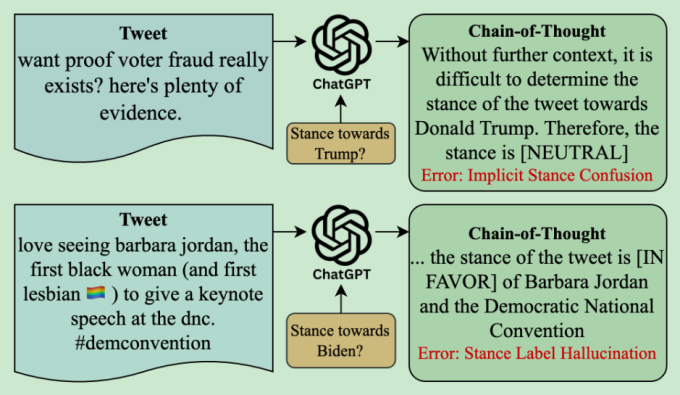
数据集:Tweet-Stance、P-Stance
Toxicity, Morality, and Speech Act Guided Stance Detection
时间:2023年12月
等级:EMNLP 2023 Findings
思想:关注一些情绪倾向
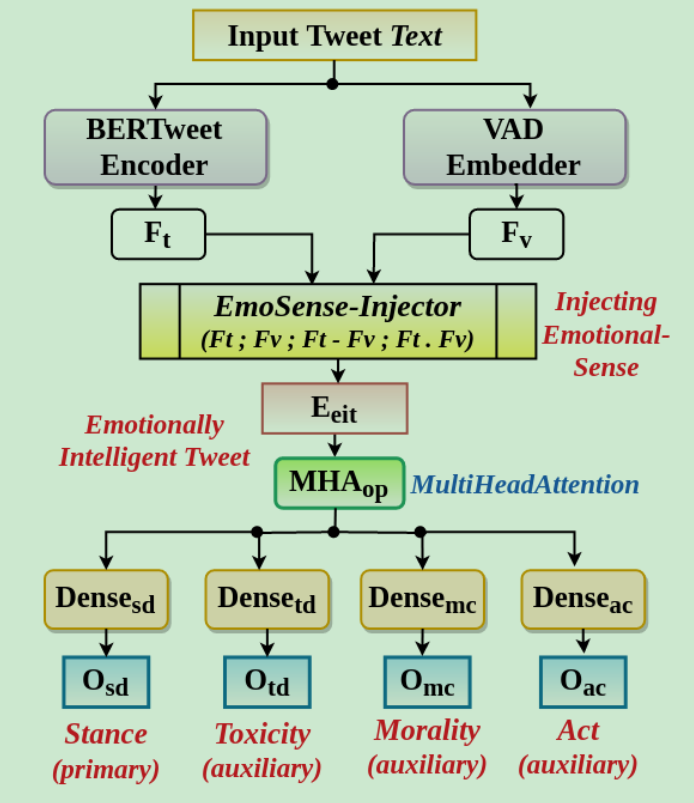
数据集:SemEval、P-Stance、Climate、COVID
Multilingual Coarse Political Stance Classification of Media. The Editorial Line of a ChatGPT and Bard Newspaper
时间:2023年12月
等级:EMNLP 2023 Findings
思想:使用大模型对人工编写的新闻的倾向进行判断,不算立场检测
数据集:与立场检测无关
2024
Cross-target Stance Detection by Exploiting Target Analytical Perspectives
时间:2024年1月
等级:Arxiv
思想:先用GPT3.5给出可以分析的视角,然后一起送到小模型中进行立场检测,同时情感词汇使用SenticNet进行扩充。比较传统的做法
数据集:SEM16和VAST
EACL 2024 气候相关立场检测竞赛
HAMiSoN-Generative at ClimateActivism 2024: Stance Detection using generative large language models
- 大模型+分类头做立场检测
- BertTweet+CNN
- 扩充了数据,然后用小模型做了微调
- 训练多个模型,包括小模型、大模型等,然后进行集成
Unsupervised Stance Detection for Social Media Discussions: A Generic Baseline
采用无监督学习的方式保证立场检测的泛化性
关于图神经网络的做法
等级:EACL 2024
SocialPET: Socially Informed Pattern Exploiting Training for Few-Shot Stance Detection in Social Media
等级:期刊
现状介绍的很详细,可以参考
也是用辩论的方式,构建多个场景然后集成一下
数据集:P-Stance
Collaborative Knowledge Infusion for Low-resource Stance Detection
等级:Arxiv
小模型+Wiki的RAG+LoRA+一些训练技巧
数据集:VAST、P-Stance、COVID-19-Stance
Stance Detection on Social Media with Fine-Tuned Large Language Models
用大模型微调的方式探索了一下立场检测使用大模型能力的边界
Zero-shot Cross-lingual Stance Detection via Adversarial Language Adaptation
有跨主题跨语言的相关工作
用一个多语言的Encoder,构建一个Pipeline做跨语言的立场检测
EDDA: An Encoder-Decoder Data Augmentation Framework for Zero-Shot Stance Detection
Coling 2024
先训一个完整的Transformer,然后将他的输出通过Prompt的方式进行多步推理的立场检测
EcoVerse: An Annotated Twitter Dataset for Eco-Relevance Classification, Environmental Impact Analysis, and Stance Detection
关于气候的新的立场检测的数据集
KPatch: Knowledge Patch to Pre-trained Language Model for Zero-Shot Stance Detection on Social Media
先扩充Topic,然后通过查询知识库的方式提取相关信息,获取知识
获取知识后先判断知识的正确性,然后再使用大模型、LoRA的方式进行立场检测
STEntConv: Predicting Disagreement with Stance Detection and a Signed Graph Convolutional Network
不用大模型,是GCN+小模型的做法
Examining Temporalities on Stance Detection Towards COVID-19 Vaccination
探索了一下新冠数据集中大家的立场随着时间的变化,用一些模型跑了一下
A Challenge Dataset and Effective Models for Conversational Stance Detection
构建了一个对话的立场检测数据集,魔改了一下Attention的结构进行立场检测
Investigating the Robustness of Modelling Decisions for Few-Shot Cross-Topic Stance Detection: A Preregistered Study
探索了不同的立场检测结构对于新闻立场检测的效果
Stance Reasoner: Zero-Shot Stance Detection on Social Media with Explicit Reasoning
Prompt+In Context+示例选择的方式,不微调大模型进行立场检测
Target-Adaptive Consistency Enhanced Prompt-Tuning for Multi-Domain Stance Detection
比较传统的Verbalizer的方法,不涉及大模型
DEEM: Dynamic Experienced Expert Modeling for Stance Detection
使用多专家的方式,多步进行推理
The Impact of Stance Object Type on the Quality of Stance Detection
claim、frame相关,构建了一套pipeline
Ad Hoc Compounds for Stance Detection
和立场检测不是很相关
Relative Counterfactual Contrastive Learning for Mitigating Pretrained Stance Bias in Stance Detection
更改了对比学习的构建数据的方式,算是对训练方法的改进,用的是小模型
Zero-Shot Stance Detection using Contextual Data Generation with LLMs
用GPT-3扩充VAST数据集
增强目前已有模型的能力
Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
还是多的角度的角色扮演,然后再对比学习什么的做一下立场检测
Reinforcement Tuning for Detecting Stances and Debunking Rumors Jointly with Large Language Models
强化学习+MOE+LoRA
Mitigating Biases of Large Language Models in Stance Detection with Calibration
分析模型的偏见,蛮复杂的
The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
(SQBC: Active Learning using LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions)
像是投ICML然后没中,投了NeurIPS
生成数据然后通过查询的方式,筛选出最有价值的没有打标签的样本
CoSD: Collaborative Stance Detection with Contrastive Heterogeneous Topic Graph Learning
通过主题模型找主题的做法
Applying the Ego Network Model to Cross-Target Stance Detection
利用社交网络信息对立场检测的效果进行增强
GunStance: Stance Detection for Gun Control and Gun Regulation
收集了一个枪支的数据集,然后进行立场检测
Multi-modal Stance Detection: New Datasets and Model
多模态的数据集和基本的方法
Tree-of-Counterfactual Prompting for Zero-Shot Stance Detection
树形的Prompt,多步推理出立场检测的标签
Transitive Consistency Constrained Learning for Entity-to-Entity Stance Detection
实体对实体的立场检测,与普通的差异较大
ZeroStance: Leveraging ChatGPT for Open-Domain Stance Detection via Dataset Generation
用ChatGPT构建数据的pipeline