LLM强化学习
LLM强化学习相关学习资料
相关链接
图解大模型RLHF系列之:人人都能看懂的PPO原理与源码解读:https://zhuanlan.zhihu.com/p/677607581
原理解析:https://blog.csdn.net/v_JULY_v/article/details/134242910
KL散度详解:https://blog.csdn.net/Rocky6688/article/details/103470437
简要版本解析:https://blog.csdn.net/u014386899/article/details/136633074
代码解读:https://zhuanlan.zhihu.com/p/696044978
强化学习
基本概念
状态迁移函数:
:输入状态
:行动
:下一个状态
状态迁移概率:
奖励函数:
策略:
- 确定性策略:
- 随机性策略:
,在状态
智能代理根据策略
收益:
:折现率(引入折现率主要是为了防止连续性任务的收益变得无穷大)
状态价值函数:
- 条件概率:
至少存在一个最优策略
成立,当输入状态
贝尔曼方程
意义:将无限的计算转换为有限的联立方程。
状态价值函数的贝尔曼方程
表示当前状态的价值函数与下一状态的价值函数的关系
推导过程:
①
②
最终相加:
行动价值函数的贝尔曼方程
行动价值函数(Q函数):在状态价值函数的基础上加行动
与状态价值函数的转换关系:
贝尔曼方程:
①
②
最终相加:
换掉$v_{\pi}(s^{\prime}) $
贝尔曼最优方程:对最优策略
最优行动
动态规划法求解
- 策略评估:求给定策略
的价值函数
和
- 策略控制:控制策略并转换为最优的策略。
联立方程,未知数的数量可能非常多,因此采用动态规划法进行策略评估。
将贝尔曼方程转化为更新式:(迭代策略评估)
如果状态迁移是确定性的
策略改进:
价值迭代法:融合了策略评估阶段和策略改进阶段
NLP中的强化学习
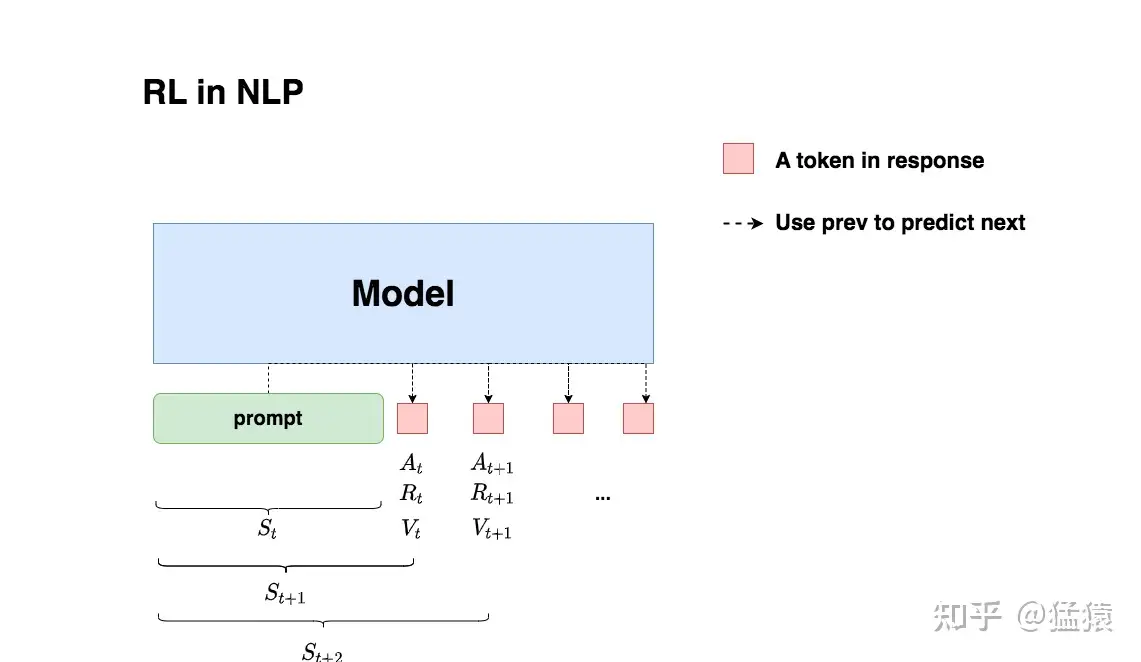
:模型根据上文,产生一个token
:即时收益,指语言模型当下产生token
:实际期望总收益(即时+未来),指对语言模型“当下产生token
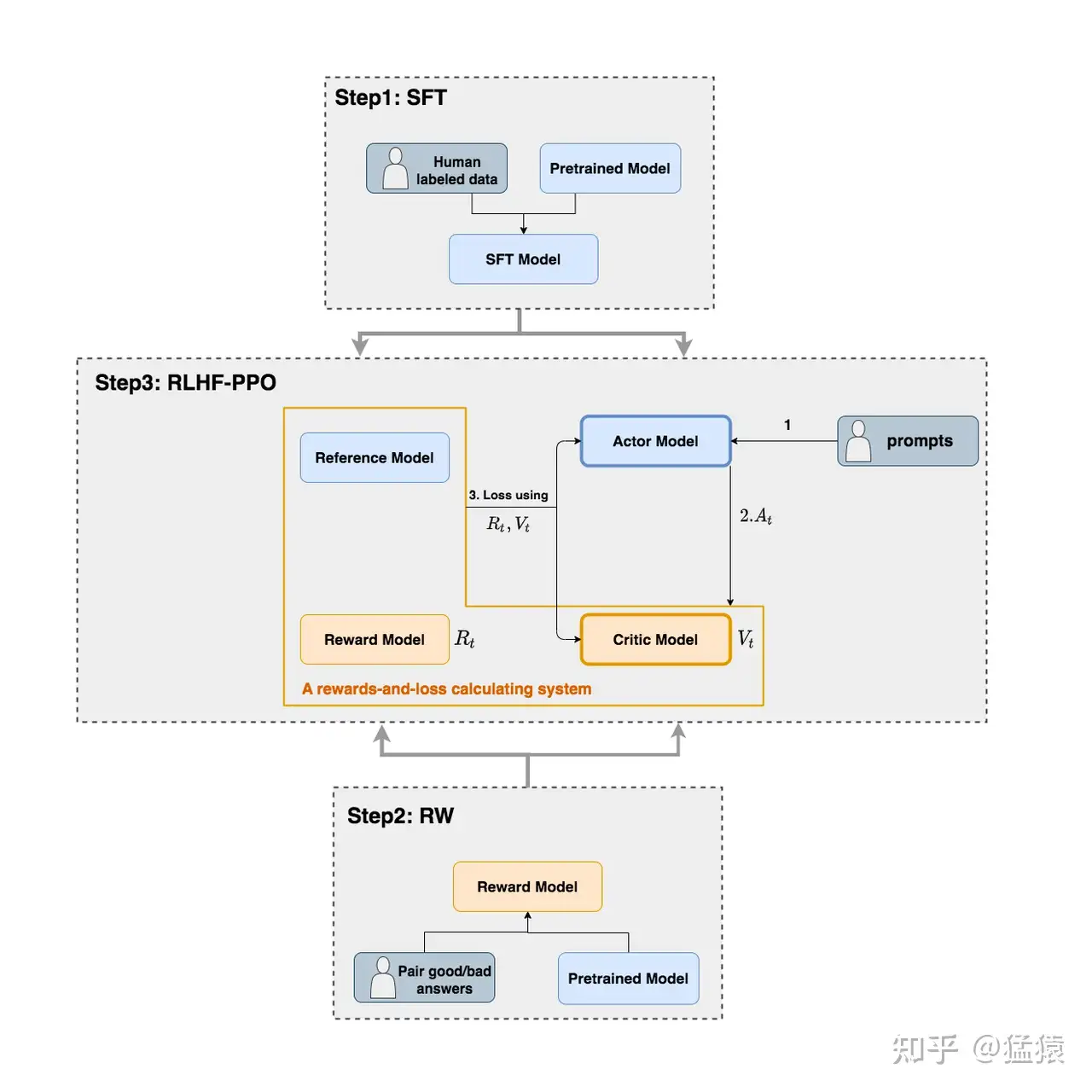
在RLHF-PPO阶段,一共有四个主要模型 ,分别是:
- Actor Model:演员模型 ,这就是我们想要训练的目标语言模型
- Critic Model:评论家模型 ,它的作用是预估总收益
- Reward Model:奖励模型 ,它的作用是计算即时收益
- Reference Model:参考模型 ,它的作用是在RLHF阶段给语言模型增加一些“约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)
Actor/Critic Model在RLHF阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model是参数冻结的。
Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系(我自己命名的,为了方便理解),我们综合它们的结果计算loss,用于更新Actor和Critic Model
Actor Model (演员模型)
Actor就是我们想要训练的目标语言模型。我们一般用SFT阶段产出的SFT模型来对它做初始化。
我们的最终目的是让Actor模型能产生符合人类喜好的response。所以我们的策略是,先喂给Actor一条prompt (这里假设batch_size = 1,所以是1条prompt),让它生成对应的response。然后,我们再将“prompt + response"送入我们的“奖励-loss”计算体系中去算得最后的loss,用于更新actor。
Reference Model(参考模型)
Reference Model(以下简称Ref模型)一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。 Ref模型的主要作用是防止Actor”训歪”
我们希望训练出来的Actor模型既能达到符合人类喜好的目的,又尽量让它和SFT模型不要差异太大 。因此我们使用KL散度来衡量输出分布的相似度
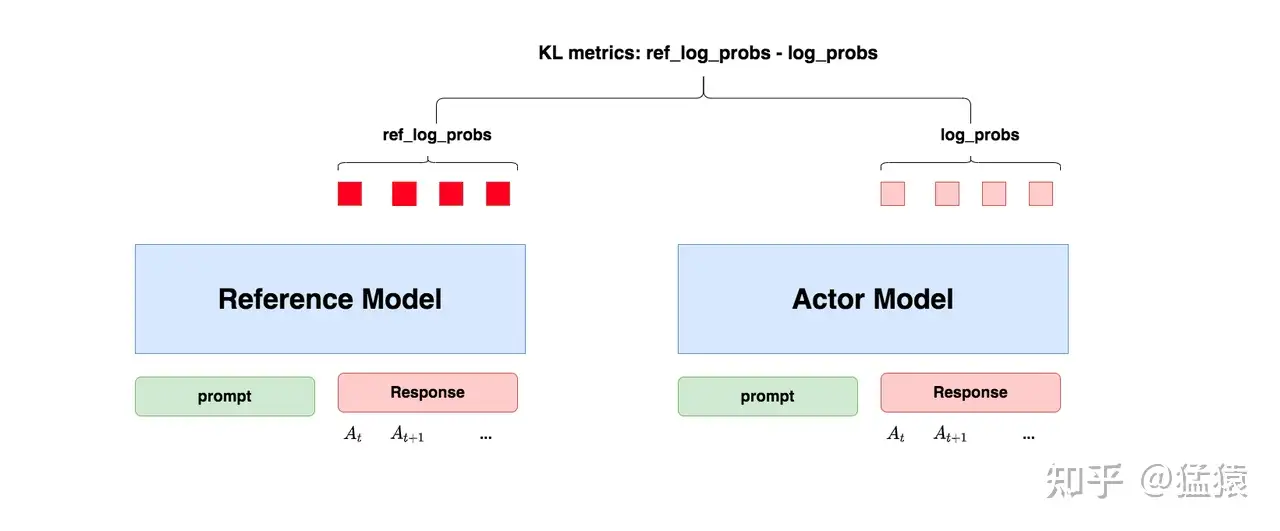
- 对Actor模型 ,我们喂给它一个prompt,它正常输出对应的response。那么response中每一个token肯定有它对应的log_prob结果,我们把这样的结果记为log_probs
- 对Ref模型 ,我们把Actor生成的"prompt + response"喂给它,那么它同样能给出每个token的log_prob结果,我们记其为ref_log_probs
- 那么这两个模型的输出分布相似度就可以用
ref_log_probs - log_probs来衡量,就是KL散度的公式- ref_log_probs越高,说明Ref模型对Actor模型输出的肯定性越大。即Ref模型也认为Actor模型较Ref模型没有训歪
Critic Model(评论家模型)
Critic Model用于预测期望总收益,和Actor模型一样,它需要做参数更新 。
在
在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)
deepspeed-chat采用了Reward模型作为它的初始化,可以简单理解成,Reward/Critic模型和Actor模型的架构是很相似的(毕竟输入都一样),同时,它在最后一层增加了一个Value Head层,该层是个简单的线形层,用于将原始输出结果映射成单一的
Reward Model(奖励模型)
Reward Model用于计算生成token的即时收益,它就是RW阶段所训练的奖励模型,在RLHF过程中,它的参数是冻结的。
Reward模型是站在上帝视角的。这个上帝视角有两层含义:
- 第一点,Reward模型是经过和“估算收益”相关的训练的,因此在RLHF阶段它可以直接被当作一个能产生客观值的模型。
- 第二点,Reward模型代表的含义就是“即时收益”,你的token
reward是对actor模型进行了某一个action之后的直接打分;而critic则是对这个actor模型的整体预估得分。每次actor模型更新后,critic模型都要对这个新的actor模型重新打分,所以critic模型也要更新参数。critic模型对actor模型的整体预估得分,是根据reward模型的每一次实时打分来预估的。当critic模型的预估得分达到了一定的基准,就代表actor模型训练完成。
RLHF-PPO的训练过程
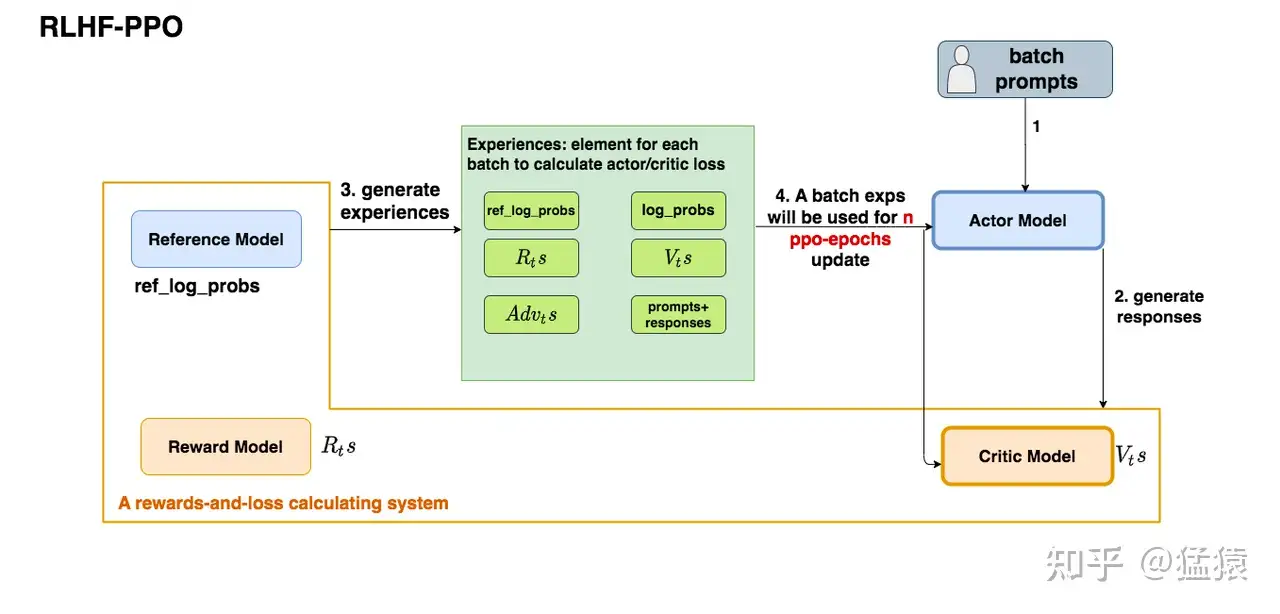
- 第一步,我们准备一个batch的prompts
- 第二步,我们将这个batch的prompts喂给Actor模型,让它生成对应的responses
- 第三步,我们把prompt+responses喂给我们的Critic/Reward/Reference模型,让它生成用于计算actor/critic loss的数据,按照强化学习的术语,我们称这些数据为经验(experiences)。
- 第四步,我们根据这些经验,实际计算出actor/critic loss,然后更新Actor和Critic模型
Loss
Actor Loss
直观设计
- Actor接收到当前上文
,产出token
- Critic model 根据
- actor loss =
- 当
时,意味着Critic对Actor当前采取的动作给了正向反馈,因此我们就需要在训练迭代中提高
,这样就能达到减小loss的作用。
- 当
时,意味着Critic对Actor当前采取的动作给了负向反馈,因此我们就需要在训练迭代中降低
- 当
引入优势
如果Critic对
actor loss =
- 当
时,我们更加关心Actor是否有在Ref的约束下生产token
- 当
时,我们不仅关心Actor是否遵从了Ref的约束,也关心真正的即时收益
为什么只有最后一个时刻的
改造优势
新引入的
对于最后一个时刻
重复使用
太慢了,所以一个batch的经验值将被用于n次模型更新
1个batch的经验值被使用ppo_epochs次,在这ppo_epochs中,Actor是不吃任何新数据,不做任何交互的,所以我们只能让Actor“模拟”一下和环境交互的过程,吐出一些新数据出来。
还是保证新的数据和旧的差不多,还是使用KL散度
actor loss =
在Actor想通过模拟交互的方式,使用一个batch的经验值更新自己时,它需要收到真正吃到batch的那个时刻的Actor的约束,这样才能在有效利用batch,提升训练速度的基础上,保持训练的稳定。
设置一个范围,差距太大就不要更新了
Critic Loss
时刻的总收益的预估,这个总收益包含即时和未来的概念(预估收益)
:Reward计算出的即时收益
及之后时候的收益的折现,这是比
更接近
第一想法:Critic loss =$ (𝑅_𝑡+ \gamma ∗𝑉_{𝑡+1}-V_t)^2$
实际收益优化:
预估收益优化:类比于Actor,Critic模型在ppo_epochs的过程中也是不断更新的。所以这个
用老
最终我们就取实际收益和预估收益的MSE做为loss就好,这里注意,计算实际收益时
DPO
DPO通过简单的分类目标直接优化最满足偏好的策略,而没有明确的奖励函数或RL
DPO的本质在于增加了被首选的response相对不被首选的response的对数概率,但它包含了一个动态的、每个示例的重要性权重,以防止设计的概率比让模型的能力退化。
核心假设:偏好数据遵循 Bradley-Terry 模型(

DPO与PPO的区别:https://zhuanlan.zhihu.com/p/11913305485
变种
IPO相当于在DPO的损失函数上添加了一个正则项,从而可以使得不使用early stopping技巧就可以使模型收敛。
KTO定义的损失函数只需要将样本标注为"好(good)“或"坏(bad)”,从而使得获取标注样本的成本更低。(就是不需要一对一对标注了)
CPO在训练期间不需要加载参考策略模型。通过省略内存的参考模型,CPO提高了操作效率,与DPO相比,能够以更低的成本训练更大的模型。
ORPO整合SFT和DPO,且不需要额外的参考模型
SimPO 包含两个主要组件:(1)在长度上归一化的奖励,其计算方式是使用策略模型的奖励中所有 token 的平均对数概率;(2)目标奖励差额,用以确保获胜和失败响应之间的奖励差超过这个差额。
SimPO 不需要参考模型,性能却明显优于 DPO 及其最新变体,且不会显著增加响应长度